If you are building an AI application or training a Large Language Model, you know that the quality of your output depends entirely on the data you feed it. Firecrawl has gained massive popularity for its ability to crawl entire websites and convert them into clean markdown.
However, as your project scales, you might encounter limitations in terms of complex site navigation, proxy management, or the need for a no code interface for web scraping.
Whether you are looking for more robust enterprise features or a simpler way to manage your web scraping agents, there are several powerful alternatives available today. Here is a guide to the best Firecrawl alternatives :
Agenty
Agenty is a premier choice for those who want the power of enterprise grade web scraping without the need for deep coding knowledge. Unlike Firecrawl, which is developer centric, Agenty provides a cloud based platform where you can set up scraping agents using a point and click interface with AI.
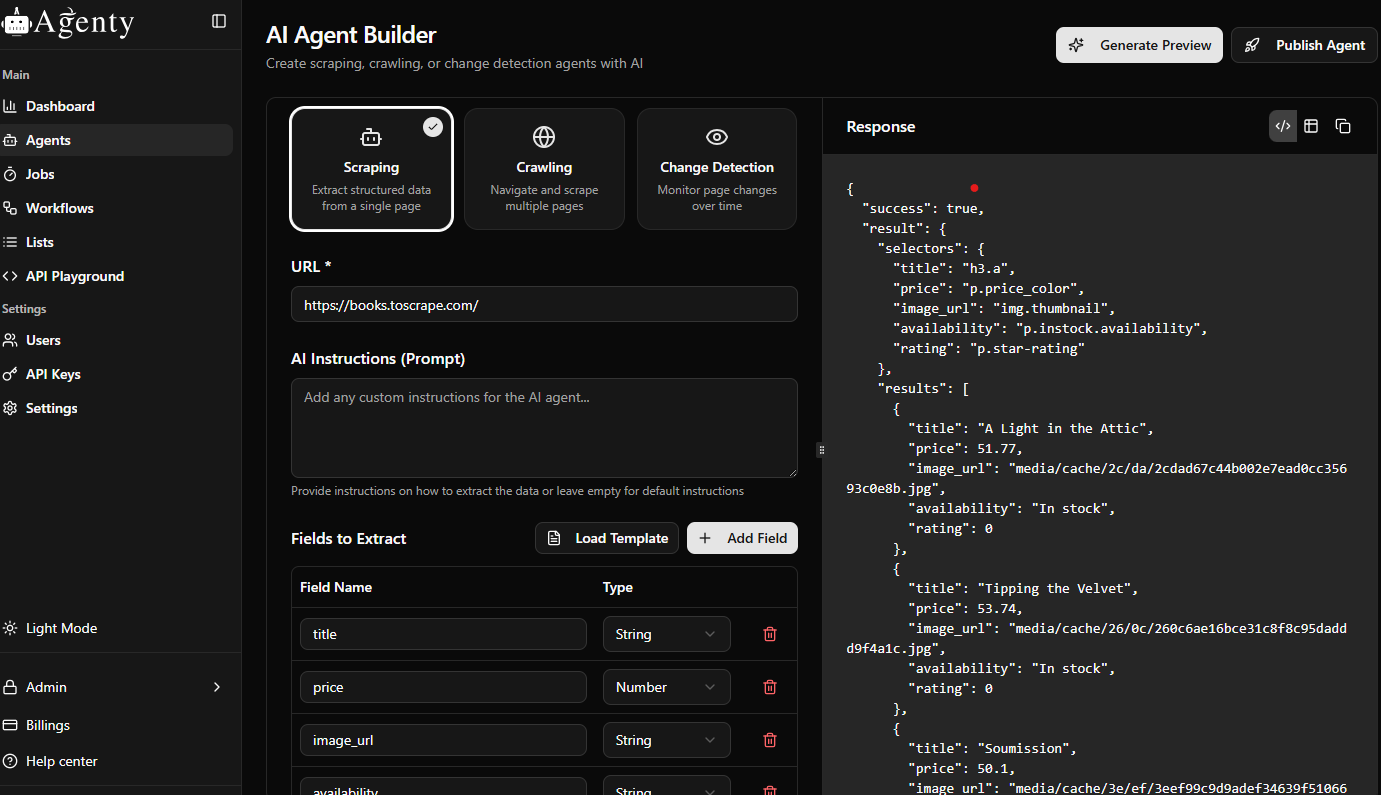
Agenty offers a browser extension that allows you to select the data you want to extract visually. It handles everything from anonymous scraping via proxies to scheduling jobs and automatic data cleaning. One of its standout features is the ability to integrate directly with various storage options like Google Sheets, Dropbox, and Amazon S3. For AI developers, Agenty can output data in JSON or CSV formats that are easily converted for LLM training.
Pros
- No code interface makes it accessible for non developers.
- Built in scheduling and cloud hosting.
- Excellent handling of complex pagination and dynamic content.
Cons
- Might be more features than needed for a simple markdown conversion.
- Learning curve for the advanced logic builder.
Browserbase
Browserbase is a developer focused platform that provides the infrastructure to run headless browsers at scale. While Firecrawl focuses on the crawling logic, Browserbase focuses on providing a reliable environment where your AI agents can interact with the web just like a human would.
It is designed to handle the complexities of modern web sessions, including authentication, state management, and anti bot bypass. If your AI needs to log into a dashboard or navigate a complex single page application before extracting data, Browserbase provides the persistent browser sessions required to do so reliably.
Pros
- Provides serverless browser infrastructure that scales automatically.
- Built in stealth mode to bypass the most advanced bot detection.
- Detailed session recordings and logs for debugging AI agent behavior.
Cons
- Requires programming knowledge to set up browser scripts.
- Focuses on the browser layer rather than the data transformation layer.
Apify
Apify is a comprehensive platform for web scraping and automation. It hosts a massive library of pre built actors which are essentially cloud based programs that can crawl specific websites like Amazon, Google Maps, or LinkedIn.
Apify provides a dedicated Website Content Crawler specifically designed to feed data into vector databases like Pinecone or LangChain. It can crawl websites, remove HTML tags, and even handle the chunking of text for you. Because it is a developer platform, you can write custom JavaScript to handle any edge case you encounter.
Pros
- Massive library of pre built scraping tools.
- Highly scalable for millions of pages.
- Integrates directly with major AI frameworks.
Cons
- Requires some coding knowledge to get the most out of it.
- Credit system can be difficult to predict for budget planning.
Diffbot
Diffbot takes a different approach by using machine learning and computer vision to understand a webpage the way a human does. Instead of relying on specific HTML tags, it identifies the parts of a page like articles, products, or discussions automatically.
The Diffbot Knowledge Graph is one of the most advanced data extraction tools on the market. It does not just scrape text; it extracts structured data. If you point it at a news site, it knows who the author is, the publish date, and the main image without you telling it where to look. This makes it incredibly resilient to website layout changes.
Pros
- Automatically handles layout changes.
- No need to write custom scraping rules.
- High quality structured data output.
Cons
- Very expensive for small projects or startups.
- Can be overkill if you only need raw text.
Zyte
Formerly known as Scrapinghub, Zyte is a veteran in the web data extraction space. They focus heavily on the infrastructure side of scraping, ensuring that your requests do not get blocked by anti bot systems.
Zyte provides an API tool that handles proxy rotation, headless browser management, and anti ban logic automatically. For Firecrawl users who are struggling with getting blocked by sites like Cloudflare, Zyte is a powerful remedy. They also offer an automatic extraction feature that uses AI to pull data from product pages and articles.
Pros
- Best in class proxy management and anti detection.
- Highly reliable for large scale enterprise crawls.
- Expert support for complex scraping challenges.
Cons
- The interface can be complex for beginners.
- Setup for specific websites can take longer than simpler tools.
Bright Data
Bright Data is widely known for having the largest proxy network in the world, but they have expanded into a full suite of scraping tools, including their Scraping Browser and Web Scraper IDE.
The Scraping Browser is particularly useful for those who want to use tools like Puppeteer or Playwright but do not want to deal with the overhead of managing browsers. It handles all the website unlocking and CAPTCHA solving internally. They also offer a Website Unblocker that acts as a bridge between your crawler and the target site.
Pros
- Unbeatable proxy network access.
- Easily handles the most difficult to scrape websites.
- Powerful IDE for building custom scrapers.
Cons
- The pricing structure can be complex to understand.
- Requires a good understanding of web technologies to implement.
Final Thoughts
Choosing the right Firecrawl alternative depends on your technical expertise and the scale of your project. If you want a no code environment with powerful cloud features, Agenty is an excellent starting point.
For those who need a robust infrastructure to run AI agents that interact with complex web apps, Browserbase is the top choice. If you are dealing with enterprise level scaling and anti bot hurdles, solutions like Zyte or Bright Data will provide the heavy duty support you need in 2026.