CSS Selectors are very common in web data scraping using Agenty chrome extension. You can use the CSS selector to extract any content from the HTML pages. Selectors are the part of the CSS rule set and select HTML elements according to its Id, class, type, attribute or pseudo-classes.
The CSS selectors are easy to understand and quick to learn, you can use our chrome extension to generate CSS selectors automatically or can type manually to test the selectors and see the result preview.
In this tutorial, we will learn some of the common CSS selectors and how to write them to extract the data from HTML pages. And you can find the complete reference here
We are going to using this HTML page with the HTML source below. The page is hosted on github and open source to try CSS selectors using web scraping agent.
Test Page - https://agenty.github.io/CSS-Selectors/
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css">
</head>
<body>
<div class="container">
<h1>Welcome to CSS Selector Test Page <small>by Agenty</small></h1>
<div class="introduction">
<p>My name is Scraping <span id="surName">Agent.</span></p>
<p id="myAddress">I live in New York</p>
<p>I have many partners:</p>
</div>
<ul id="listofPartners">
<li>Text Classifer Agent</li>
<li>Change Tracking Agent</li>
<li>Document Extractor Agent</li>
<li>OCR Agent</li>
</ul>
<p>All my partners are great!
<br> But I really like Text classifer agent!</p>
<p lang="fr" title="Hello">Bonjour</p>
<h3>I have 4 pricing plans</h3>
<p><b>I love each of them:</b></p>
<table class="table table-bordered">
<tr>
<th>Name</th>
<th>Price</th>
</tr>
<tr>
<td>Starter</td>
<td>$29</td>
</tr>
<tr>
<td>Basic</td>
<td>$49</td>
</tr>
<tr>
<td>Professional</td>
<td>$99</td>
</tr>
<tr>
<td>Enterprise</td>
<td><code>This is secret :)</code></td>
</tr>
</table>
</div>
</body>
</html>
#id selector
The #id selector uses the _id _attribute of an HTML element to scrape a specific element. The id of an element is a unique identifier of particular HTML tag, so the id selector is used to select one unique element or all elements under the id.
To extract an element with a specific id write a hash (#) character followed by the id of the element in the selector field. The difference between an id and a class is that an id can be used to identify one element whereas a class can be used to identify many elements.
Example :

The “I live in New York” extracted form this HTML example is extracted using the #myAddress selector.
.class selector
The class selector scrapes all the elements with a specific class attribute. A class to search for an element can have multiple classes. Only one of them must match and to select elements with a specific class write a period (.) character followed by the name of the class. See this example, how simple the web scraping using the class.
Example
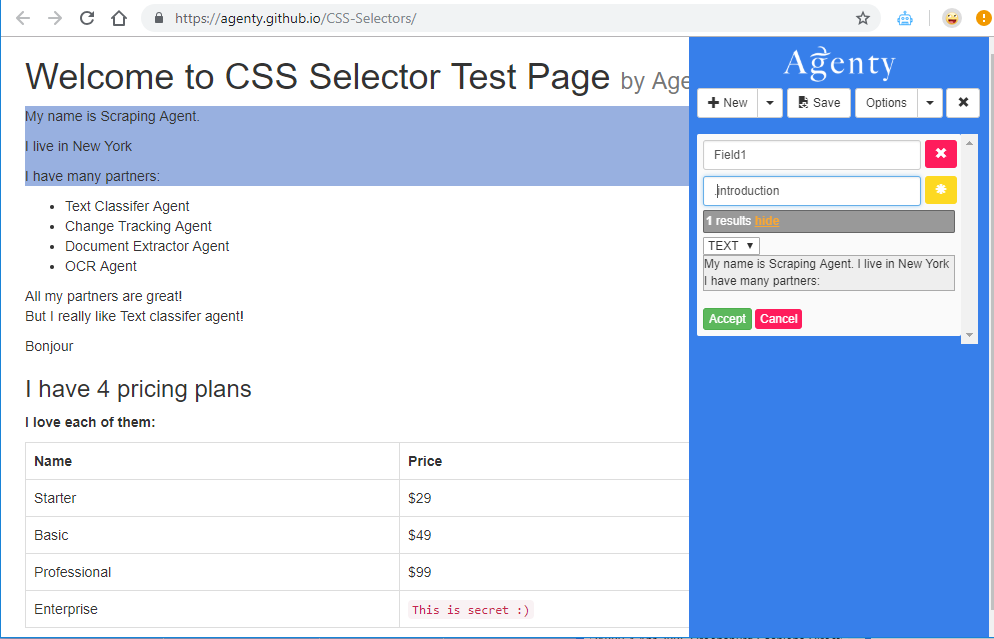
As in the above screenshot, Agenty scraped each matching element using .introduction class in this HTML example. So we can use the class selectors to scrape data from HTML pages using .class selector.
Wildcard selector
The wildcard selector (*, ^ and $) selects all elements in a page, and is very useful when trying to do a global scraping of any element. Essentially, you can use it to target every single element on the page or with an combination of attributes matching substring of given class, string etc.
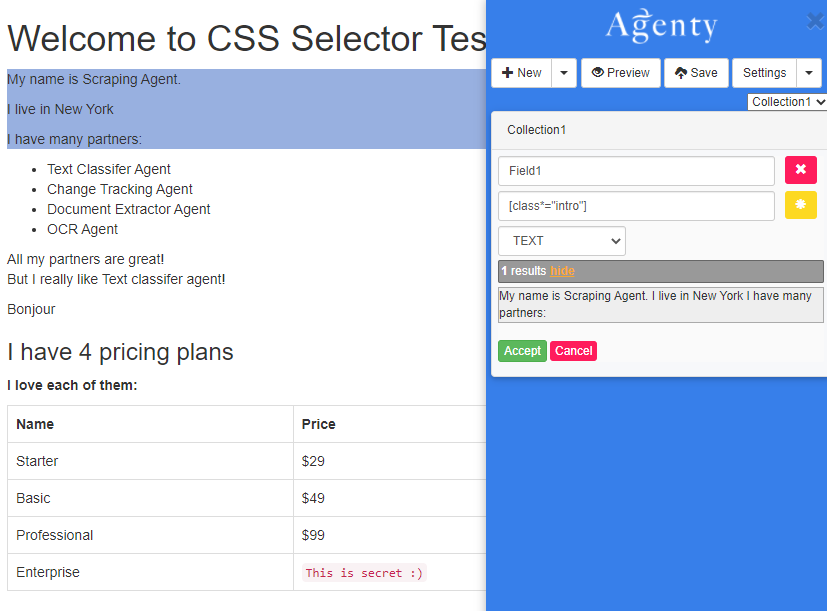
The [attribute*="value"] selector used to select and extract the elements whose attribute value contains the specified substring value . This example shows how to use a wildcard to select all div with a class that contains intro in this example.
[class*="intro"]
So, using this wildcard selector we were able to match the introduction class with attribute which contains intro substring to extract the text successfully.
HTML
<div class="introduction">
<p>My name is Scraping <span id="surName">Agent.</span></p>
<p id="myAddress">I live in New York</p>
<p>I have many partners:</p>
</div>
Universal * selector
The universal * selector scrape all the elements available on the page to extract the text from all elements.
Example
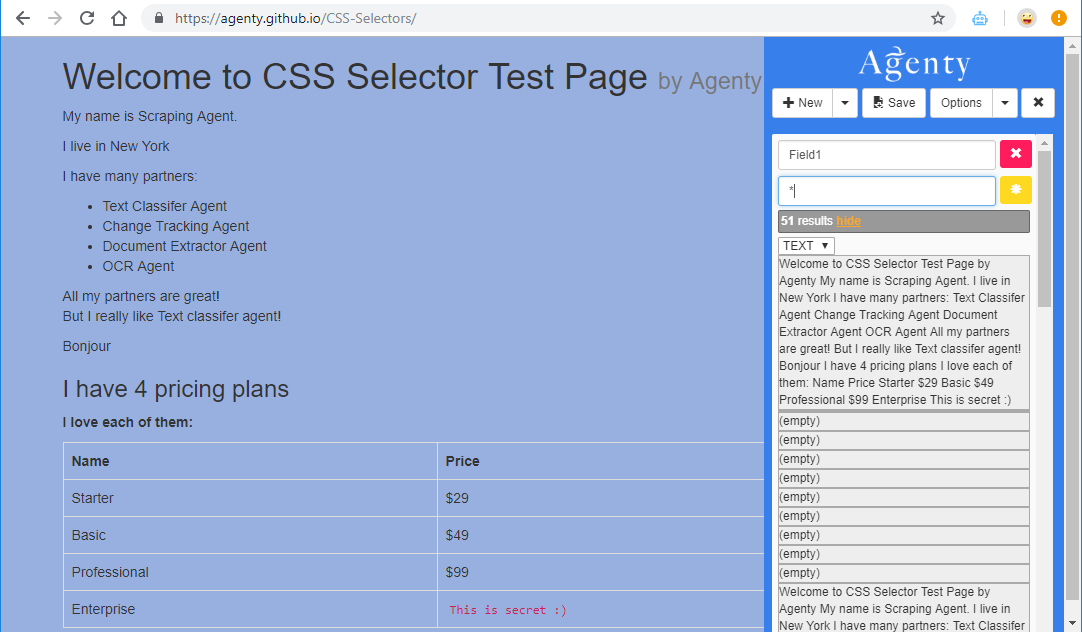
As in the screenshot given above, Agenty extracted each item which is under the <body> tag.
element selector
The element selector scrapes all elements with the specified element name.
The td element defines standard cells in the HTML table. Here we can see the data of the table extracted using the td element selector. So, we can use the name of the element to extract any data from all the elements of that type.
**Example **
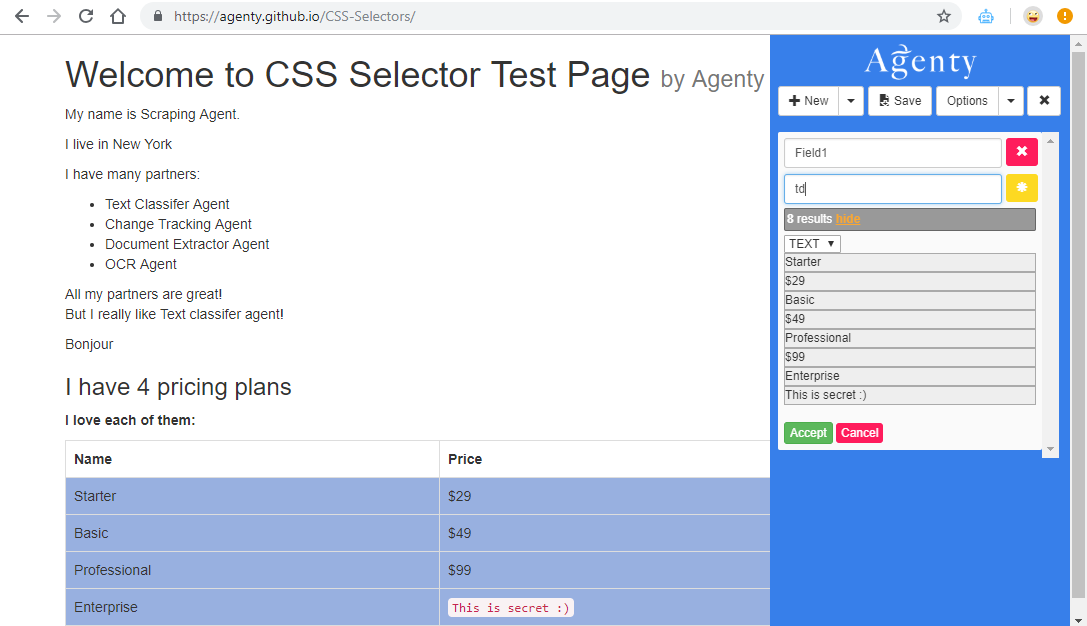
As given in the above example, Agenty scraped all 8 td elements items containing from the table.
element, element selector
The element, element selector are used to scrape all elements that are placed immediately after (not inside) the first specified element.
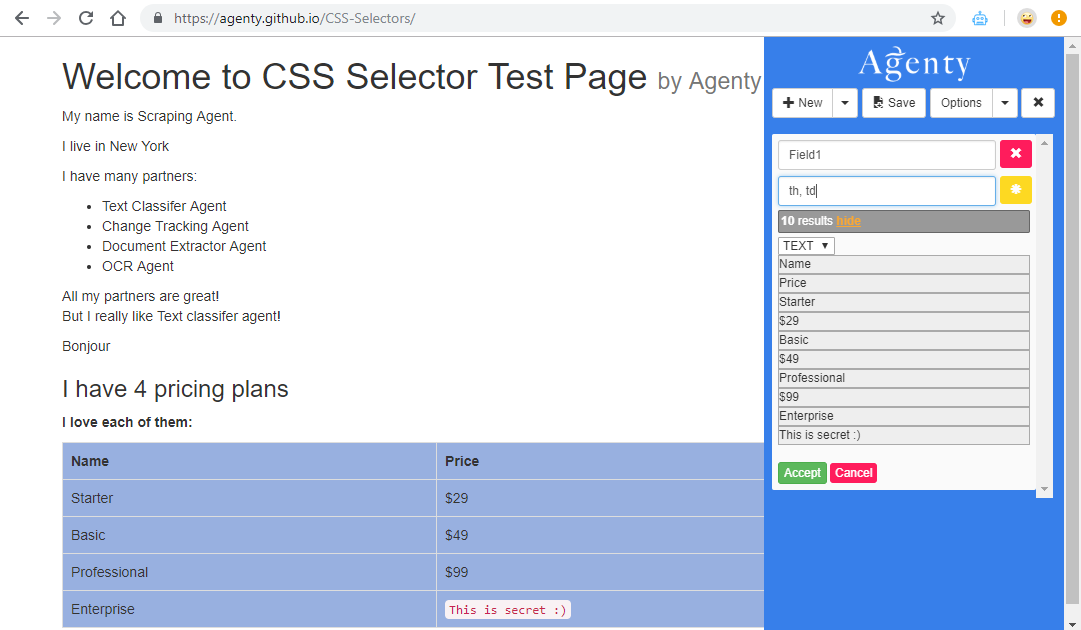
You can specify any number of selectors to combine into a single result. This multiple expression combination is an efficient way to scrape multiple data-points into the single field. For example, using the th, td selector will scrape the text for both elements - table header and table rows.
We can add any number of elements(or selector) separated by commas to scrape multiple data points.
Example
element element selector
The element element selector is used to extract elements inside elements.
When we are extracting the data, which is present in a particular parent tag. We can write our selector using the parent tag to extract only the element having the parent name provided. For example, If I want to extract the 3 paragraphs under the div tag with introduction class. I can use the .introduction p selector which will match only the p which has the parent as .introduction and not any others.
**Example **

element > element selector
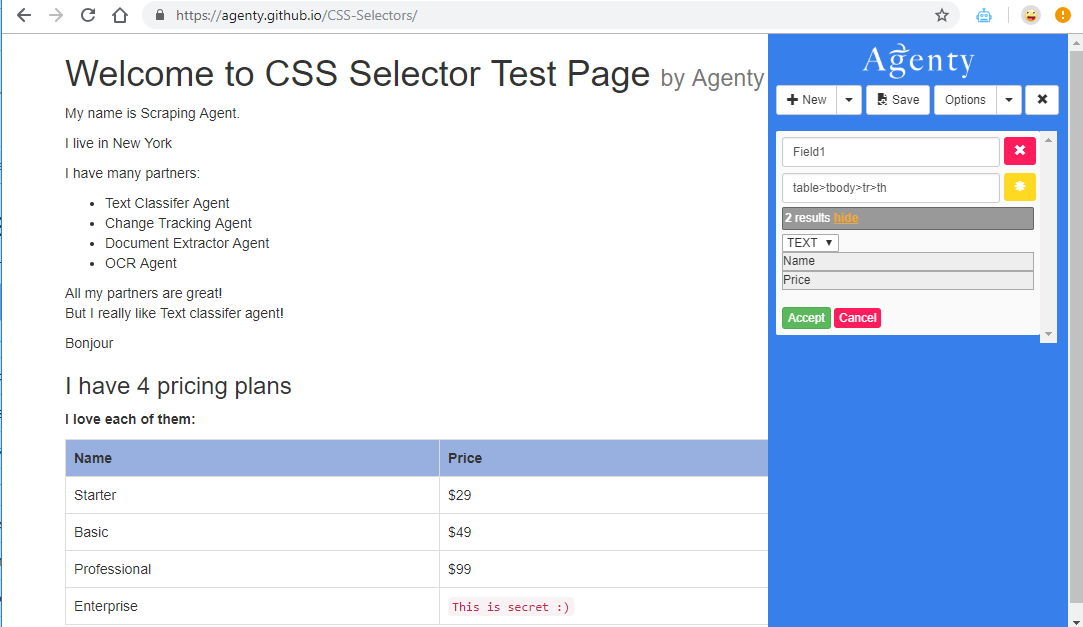
The element > element selector is used to scrape elements with a specific parent. But elements that are not directly a child of the specified parent, are not scraped.
This selector is used to extract content with direct Parent > Child relationship. For example, using table > tbody > tr > th tells Agenty, that extracts all elements where the parent is a table > tbody > tr elements
Example
:nth-child selector
The nth-child selector can be used to extract n number of items from list, rows etc. For example, if we want to scrape the top 2 rows from this given table. We can use the :nth-child(-n+2) selector to extract data from top 2 rows only -
- nth-child(2) : Scrape data from the 2nd child only
- nth-child(n+2) : Scrape data from all rows, except the first child
- nth-child(-n+2) : Scrape data from the first 2 child
- nth-child(3n+2) : Scrape data from every 3rd row starting from 2nd child
- nth-child(odd) : Scrape data from the odd number child’s only
- nth-child(even) : Scrape data from the even number child’s only
- nth-last-child(2) : Scrape data from the 2nd last child only
Scrape first 2 child’s
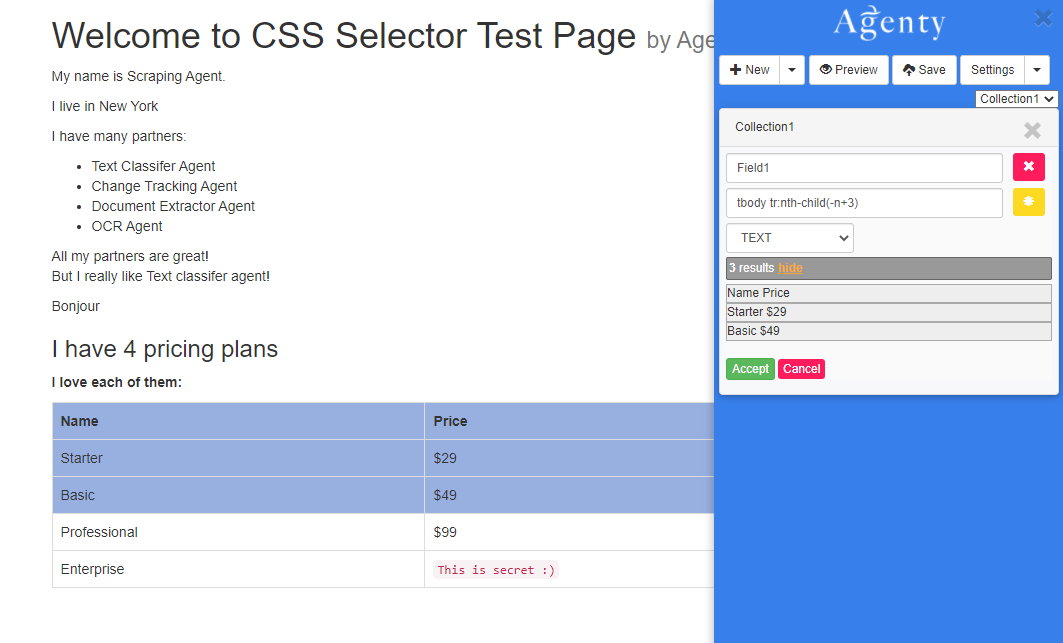
To scrape the top 2 rows only, we can use the nth-child selector. For example, If we need to extract this table’s first 2 rows. We can use this selector and exclude the heading using :not selector -
`tbody tr:nth-child(-n+3)`
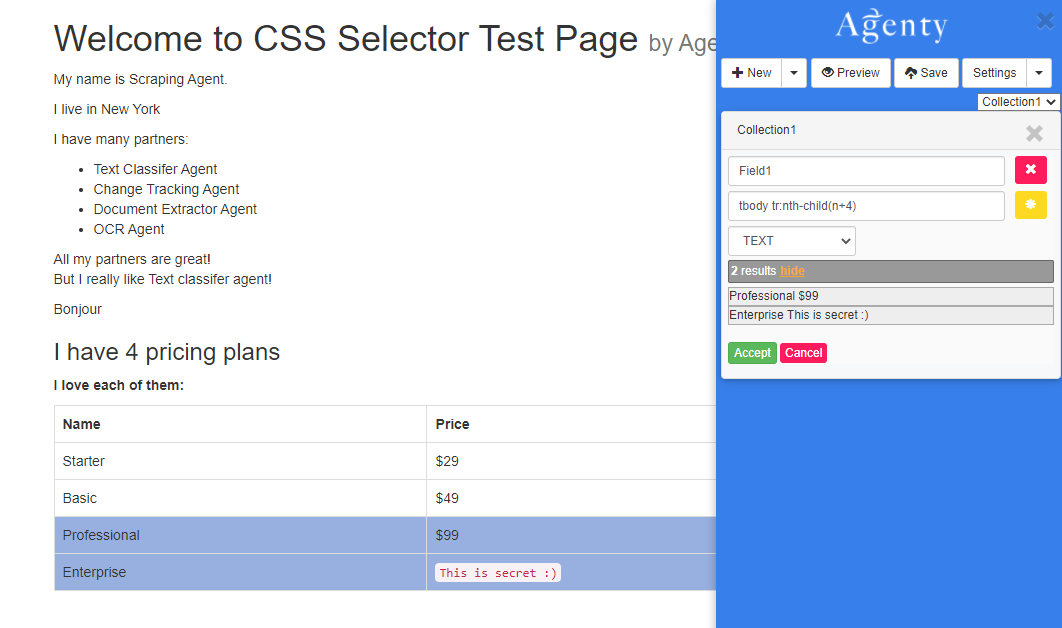
Scrape all, but the first three
tbody tr:nth-child(n+4)
Scrape all rows, except first 3 rows using n+4
:not selector
The :not CSS selector is a pseudo selector, it allows you to select elements that do not match a specified selector or set of rules. In other words, it lets you create exceptions to the rule.
For, example if want to exclude headings while scraping data from the table. We can just wrap the tr with :not selector to exclude first row (which has headings). For example - tbody tr:not(:nth-child(1))
