In this article, we’ll see how to use the scraping agent with Puppeteer to control the Chromium headless browser in Node.js for web scraping.
Puppeteer is an open-source Node.js library which provides a high-level API to control headless Chrome to do almost everything automatically for browser automation. The Agenty’s Puppeteer integration allows you to run your Puppeteer scripts on Agenty cloud backed by hundreds of servers in multiple regions for performance and scaling.
Prerequisite
There are only two things that will be needed:
- Knowledge of Node.js / Puppeteer scripting
- An Agenty account to access the Puppeteer code editor
The only thing that you need to know about Node.js is that it is a runtime framework and basics of CSS to find the selectors.
In this puppeteer tutorial, I will demonstrate a product scraping example using a sandbox eCommerce website to show how to scrape products with pagination using Puppeteer.
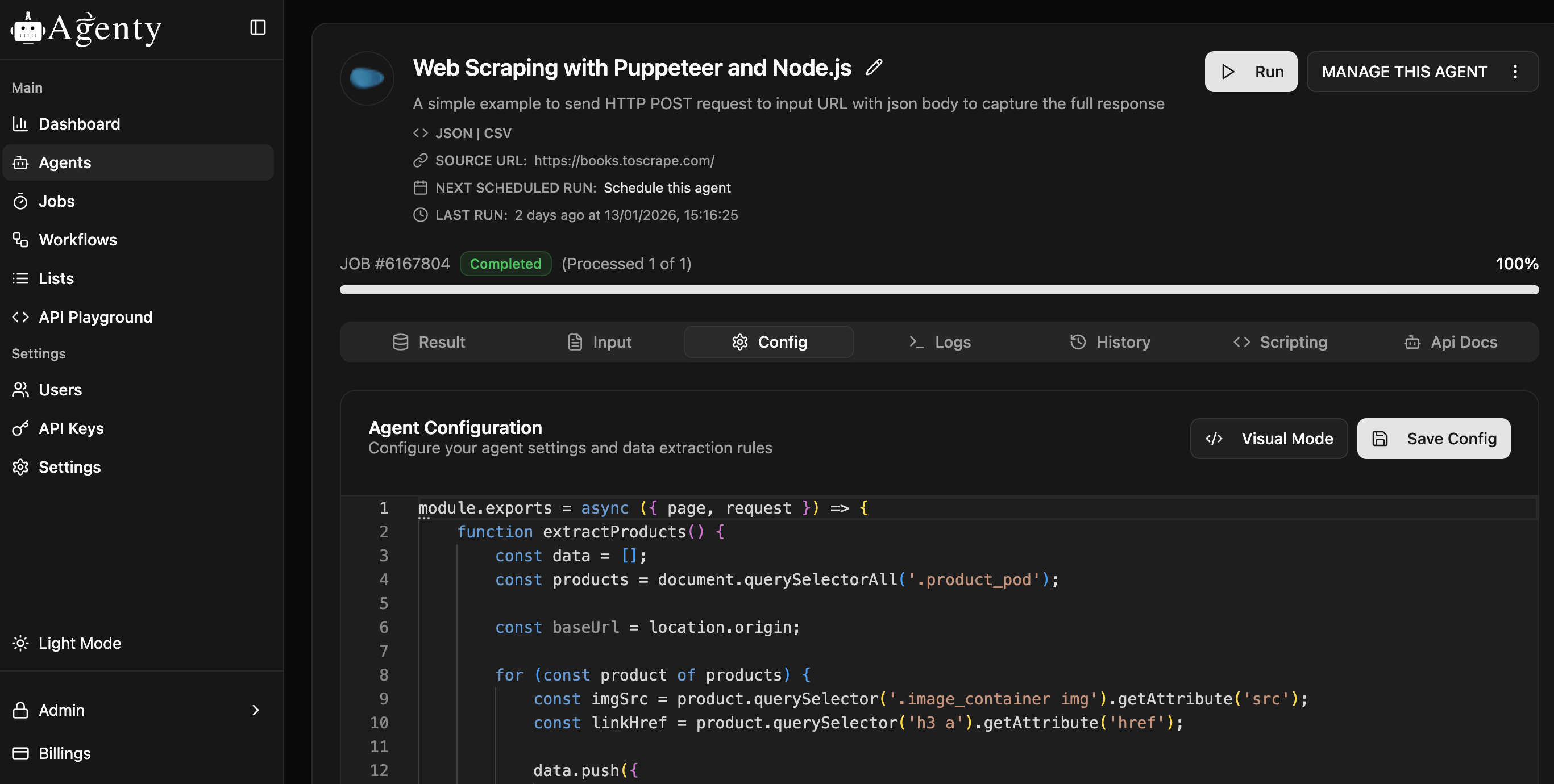
Full code
// Read the `url` from request, goto the page, extract products
// click on next button and repeat until maxPages, then return the results
module.exports = async ({ page, request }) => {
function extractProducts() {
const data = [];
var products = document.querySelectorAll('.product_pod');
for (var product of products) {
data.push({
product_name: product.querySelector('h3').textContent,
product_price: product.querySelector('.price_color').textContent,
product_availability: product.querySelector('.availability').textContent,
product_image: product.querySelector('.thumbnail').getAttribute("src"),
product_link: product.querySelector('h3 > a').getAttribute("href")
});
}
return data;
}
async function paginateAndScrape(page) {
const result = [];
for(var p = 0; p < maxPages; p++){
let products = await page.evaluate(extractProducts);
console.log(`Found ${products.length} products on page ${p}`);
// push products result array;
result.push(...products);
// Click on next button
console.log('Click next...');
await page.click('.next a');
await sleep(1000);
}
return result;
}
console.log('Navigating...');
await page.goto(request.url);
const maxPages = request.maxPages || 3;
const result = await paginateAndScrape(page);
return {
data: result,
type: 'application/json'
};
};
Code breakdown
Navigate to website
The page.goto method is used to navigate to a website URL.
await page.goto(request.url);
Pagination and Scraping
Here, I am doing pagination and scraping with puppeteer, using for loop to run the extract function for 3 pages, to extract the products and then click on the next button.
async function paginateAndScrape(page) {
const result = [];
for(var p = 0; p < maxPages; p++){
let products = await page.evaluate(extractProducts);
console.log(`Found ${products.length} products on page ${p}`);
// push products result array;
result.push(...products);
// Click on next button
console.log('Click next...');
await page.click('.next a');
await sleep(1000);
}
return result;
}
Extract fields
The extractProducts function is used to extract the product fields using querySelector get the text or attribute for given CSS selectors and then push the values in the data array.
If you are new to Agenty? You can use our Chrome extension to setup/find CSS selector for web scraping using Puppeteer.
function extractProducts() {
const data = [];
var products = document.querySelectorAll('.product_pod');
for (var product of products) {
data.push({
product_name: product.querySelector('h3').textContent,
product_price: product.querySelector('.price_color').textContent,
product_availability: product.querySelector('.availability').textContent,
product_image: product.querySelector('.thumbnail').getAttribute("src"),
product_link: product.querySelector('h3 > a').getAttribute("href")
});
}
return data;
}
Execution
In this line I am calling the paginateAndScrape function which will loop through each page to extract the products and return the result as JSON array.
const result = await paginateAndScrape(page);
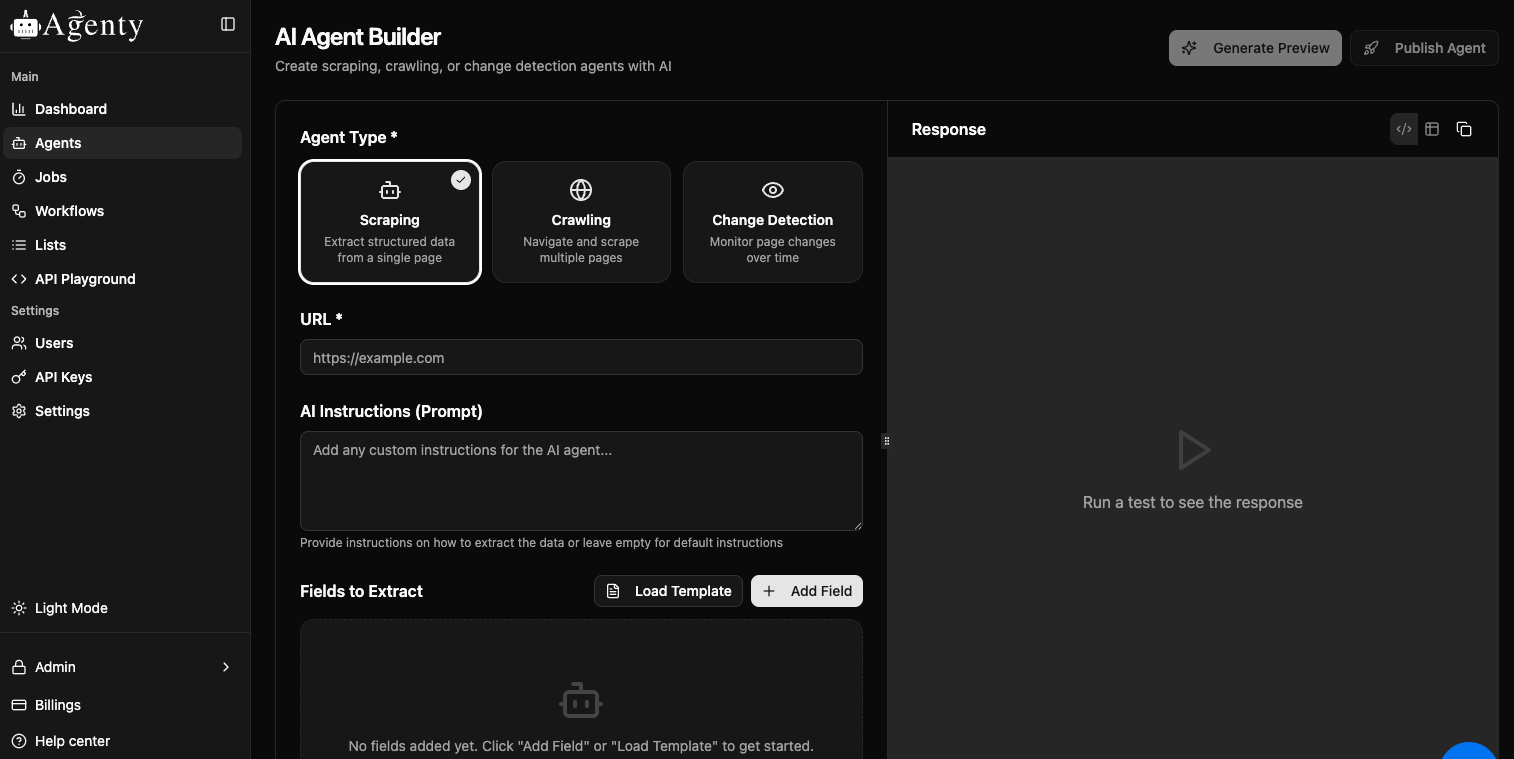
Create a scraping agent
Let’s see how we can create the scraping agent:
- Just login to your agenty account > Agents
- Click on
+Create Agents> select Agent Type (scraping agent) - Add URL > add fields(or choose templates) as per your requirements
- Run the agent and check if the details is correct then publish it
Edit script on your scraping agent
After save your agent if you want to edit your script you can do it in your scraping agent directly. Just go to your agenty dashboard > Agents > select agent( you want to edit) > Configuration
Running Puppeteer script for batch URL
Remember, I have used the request.url in page.goto() method to send the URL dynamically using the API or Agenty cloud portal.
await page.goto(request.url);
So, if we change the agent input as MANUAL and enter multiple URLs in the input box, Agenty will run the Puppeteer script by sending the request object with each URL dynamically. For example…
Request 1
{
"url": "http://books.toscrape.com/catalogue/category/books/travel_2/index.html",
"code" : "Your puppeteer script"
}
Request 2
{
"url": "http://books.toscrape.com/catalogue/category/books/fiction_10/index.html",
"code" : "Your puppeteer script"
}
and so on…
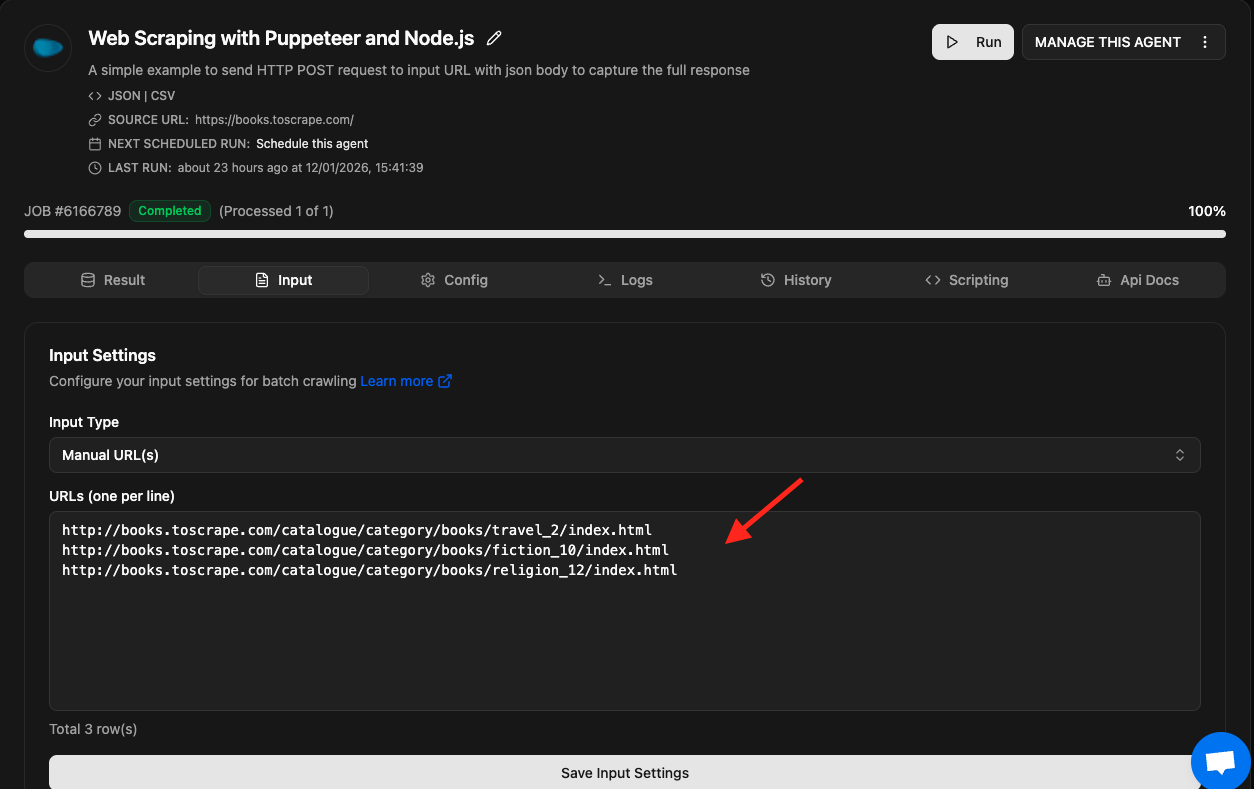
After the run is completed, you can download the result as CSV, TSV or JSON.

Execute Puppeteer script using API
You can also use our API to send a POST request to run your puppeteer script on cloud. See this example where I’ve used the node-fetch NPM package to send a POST request to chrome.agenty.com which will execute my script on cloud and return the response JSON.
const fetch = require('node-fetch');
const jsonBody ={
"code": "// Read the `url` from request, goto the page, extract products\n// click on next button and repeat until maxPages, then return the results\n\nmodule.exports = async ({ page, request }) => {\n function extractProducts() {\n const data = [];\n var products = document.querySelectorAll('.product_pod');\n for (var product of products) {\n data.push({\n product_name: product.querySelector('h3').textContent,\n product_price: product.querySelector('.price_color').textContent,\n product_availability: product.querySelector('.availability').textContent,\n product_image: product.querySelector('.thumbnail').getAttribute(\"src\"),\n product_link: product.querySelector('h3 > a').getAttribute(\"href\")\n });\n }\n return data;\n }\n \n async function paginateAndScrape(page) {\n const result = [];\n for(var p = 0; p < maxPages; p++){\n let products = await page.evaluate(extractProducts);\n console.log(`Found ${products.length} products on page ${p}`);\n \n // push products result array;\n result.push(...products);\n \n // Click on next button\n console.log('Click next...');\n await page.click('.next a');\n await sleep(1000);\n }\n return result;\n }\n \n console.log('Navigating...');\n await page.goto(request.url);\n\n const maxPages = request.maxPages || 3;\n const result = await paginateAndScrape(page);\n \n return {\n data: result,\n type: 'application/json'\n };\n};",
"request": {
"url": "http://books.toscrape.com/",
"maxPages": 3
}
};
fetch('https://chrome.agenty.com/function?apiKey={{YOUR API KEY HERE}}', {
method: 'post',
body: jsonBody,
headers: { 'Content-Type': 'application/json' },
})
.then(res => res.json())
.then(json => console.log(json));
Response
{
"data": [
{
"product_name": "A Light in the ...",
"product_price": "£51.77",
"product_availability": "In stock",
"product_image": "media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg",
"product_link": "catalogue/a-light-in-the-attic_1000/index.html"
},
{
"product_name": "Tipping the Velvet",
"product_price": "£53.74",
"product_availability": "In stock",
"product_image": "media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg",
"product_link": "catalogue/tipping-the-velvet_999/index.html"
},
...
],
"logs": [
"INFO - Navigating...",
"INFO - Found 20 products on page 0",
"INFO - Click next...",
"INFO - Found 20 products on page 1",
"INFO - Click next...",
"INFO - Found 20 products on page 2",
"INFO - Click next..."
],
"files": []
}
Puppeteer Examples
See more puppeteer examples scripts available on our Github repository open-sourced for learning and experiment Puppeteer for web scraping. Or see the puppeteer tutorial here
