Scraping Chinese or Japanese language text websites is easy in Agenty, the application automatically detects and applies the correct character encoding, and foreign language displayed on the website header when you create the web scraping agent using the Chrome extension.
The web scraping agent will automatically read the text in its native language given in header encoding. And we can also change the encoding manually by editing the scraping agent, if the default encoding doesn’t work correctly or incorrectly set by the website developers. This happens usually when the website is using another language or charset, then the one which is mentioned in the website header. For example, the HTML code given below in this Japanese website header tells that the character encoding used is charset=shift_jis
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html lang="ja" xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=shift_jis">
Encoding
Agenty automatically try to apply the correct website encoding given in header, and fall back to UTF8 if it can’t due to 1) Incorrect value. 2) Parse error etc. Here, we can set the manual encoding as well to explicitly tell Agenty what encoding should be used to scrape the page you are running using the web scraping agent to scrape data from this Japanese website:
-
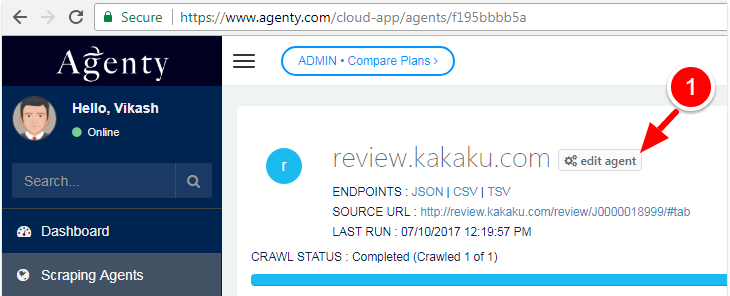
Edit the scraping agent by clicking on the
Edit agentbutton : -
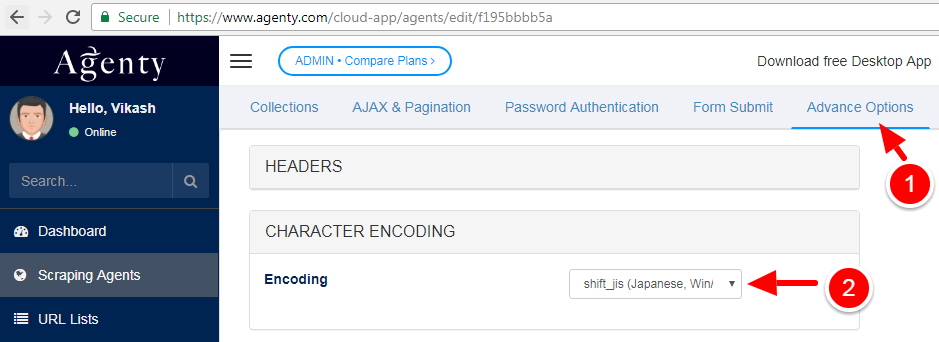
Go to
Advance Optionstab and then select the correct encoding in Character Encoding option as in screenshot given below : -
Savethe agent back and re-run it.
Execution
After the correct encoding, configuration is applied in your agent, the Agenty will produce the output correctly in clean format for any foreign language, like: Japanese, Chinese, Arabic, Cyrillic…etc.). For example, if you see the screenshot below, I ran the kakaku agent, the text is formatted correctly in the output table with the same Japanese language as on the website. So, whether it’s Chinese text, Japanese text or any other language, as long as the correct encoding is selected in Agenty online scraping app, the web scraper will extract the text exactly as it appears on the website or displayed on any other browser like Chrome or Firefox.

Output
Once the scraping job is completed and output is ready in the table, you can download the output in CSV, TSV or JSON format. We recommend the TSV(Tab Delimited) format for Non-English language websites as that’s the format used to extract and store the web data on cloud-server and converted into different formats on download requests.
[
{
"Field1": "2017年8月9日 09:42 [1052570-2]",
"Field2": "デザイン5\n携帯性5\nボタン操作5\n文字変換5\nレスポンス5\nメニュー5\n画面表示5\n通話音質無評価\n呼出音・音楽5\nバッテリー無評価\n\n\n\n\n満足度5"
},
{
"Field1": "2017年8月6日 10:40 [1051822-1]",
"Field2": "デザイン3\n携帯性4\nボタン操作3\n文字変換3\nレスポンス3\nメニュー2\n画面表示4\n通話音質4\n呼出音・音楽3\nバッテリー3\n\n\n\n\n満足度2"
},
{
"Field1": "2017年8月1日 21:49 [1050666-1]",
"Field2": "デザイン5\n携帯性5\nボタン操作5\n文字変換3\nレスポンス4\nメニュー5\n画面表示5\n通話音質5\n呼出音・音楽5\nバッテリー5\n\n\n\n\n満足度5"
},
{
"Field1": "2017年7月27日 10:49 [1045187-3]",
"Field2": "デザイン4\n携帯性4\nボタン操作4\n文字変換2\nレスポンス3\nメニュー3\n画面表示3\n通話音質3\n呼出音・音楽3\nバッテリー5\n\n\n\n\n満足度4"
},
{
"Field1": "2017年7月23日 19:08 [1048222-1]",
"Field2": "デザイン5\n携帯性3\nボタン操作3\n文字変換5\nレスポンス3\nメニュー3\n画面表示5\n通話音質3\n呼出音・音楽3\nバッテリー5\n\n\n\n\n満足度4"
},
{
"Field1": "2017年7月20日 07:25 [1047291-1]",
"Field2": "デザイン5\n携帯性5\nボタン操作5\n文字変換5\nレスポンス5\nメニュー3\n画面表示5\n通話音質5\n呼出音・音楽5\nバッテリー5\n\n\n\n\n満足度5"
},
{
"Field1": "2017年7月18日 23:31 [1010901-2]",
"Field2": "デザイン5\n携帯性3\nボタン操作4\n文字変換5\nレスポンス5\nメニュー5\n画面表示5\n通話音質5\n呼出音・音楽5\nバッテリー5\n\n\n\n\n満足度5"
},
{
"Field1": "2017年7月18日 18:04 [1046921-1]",
"Field2": "デザイン5\n携帯性4\nボタン操作5\n文字変換3\nレスポンス5\nメニュー4\n画面表示5\n通話音質無評価\n呼出音・音楽無評価\nバッテリー5\n\n\n\n\n満足度5"
},
{
"Field1": "2017年7月13日 22:30 [1045327-1]",
"Field2": "デザイン4\n携帯性4\nボタン操作4\n文字変換無評価\nレスポンス4\nメニュー3\n画面表示4\n通話音質4\n呼出音・音楽3\nバッテリー5\n\n\n\n\n満足度4"
},
{
"Field1": "2017年7月13日 19:27 [1044888-2]",
"Field2": "デザイン3\n携帯性4\nボタン操作3\n文字変換無評価\nレスポンス3\nメニュー3\n画面表示5\n通話音質4\n呼出音・音楽5\nバッテリー4\n\n\n\n\n満足度4"
},
{
"Field1": "2017年7月9日 04:05 [1043954-1]",
"Field2": "デザイン4\n携帯性5\nボタン操作2\n文字変換2\nレスポンス3\nメニュー4\n画面表示5\n通話音質3\n呼出音・音楽5\nバッテリー3\n\n\n\n\n満足度3"
},
{
"Field1": "2017年7月9日 02:23 [1043949-1]",
"Field2": "デザイン3\n携帯性2\nボタン操作3\n文字変換3\nレスポンス2\nメニュー3\n画面表示4\n通話音質4\n呼出音・音楽3\nバッテリー4\n\n\n\n\n満足度2"
},
{
"Field1": "2017年7月7日 17:50 [1043528-1]",
"Field2": "デザイン5\n携帯性5\nボタン操作5\n文字変換無評価\nレスポンス3\nメニュー4\n画面表示5\n通話音質2\n呼出音・音楽5\nバッテリー3\n\n\n\n\n満足度4"
},
{
"Field1": "2017年7月5日 11:28 [1042880-1]",
"Field2": "デザイン5\n携帯性4\nボタン操作4\n文字変換3\nレスポンス4\nメニュー4\n画面表示4\n通話音質無評価\n呼出音・音楽4\nバッテリー4\n\n\n\n\n満足度5"
},
{
"Field1": "2017年7月4日 07:31 [1042520-1]",
"Field2": "デザイン4\n携帯性4\nボタン操作4\n文字変換4\nレスポンス5\nメニュー4\n画面表示5\n通話音質無評価\n呼出音・音楽4\nバッテリー3\n\n\n\n\n満足度5"
}
]
Accept Language Header
Be sure, your Accept-Language header in header section is set to * (asterisk) to allow HTTP readers to accept any language websites like Chinese, German, French etc.
Or you can use the specific language code in value as well - For example :
-
Chinese -
Accept-Language: zh -
English -
Accept-Language: en -
French -
Accept-Language: fr -
Spanish -
Accept-Language: es -
German -
Accept-Language: de -
Japanese -
Accept-Language: ja
How to find the correct encoding
Now, the question is how to find the correct encoding used by a website and what if a website is using some other encoding in actual while mentioning something else in the header charset. Yes, there might be some cases where the character encoding mentioned in charset is different then actual or may be nothing mentioned as well.
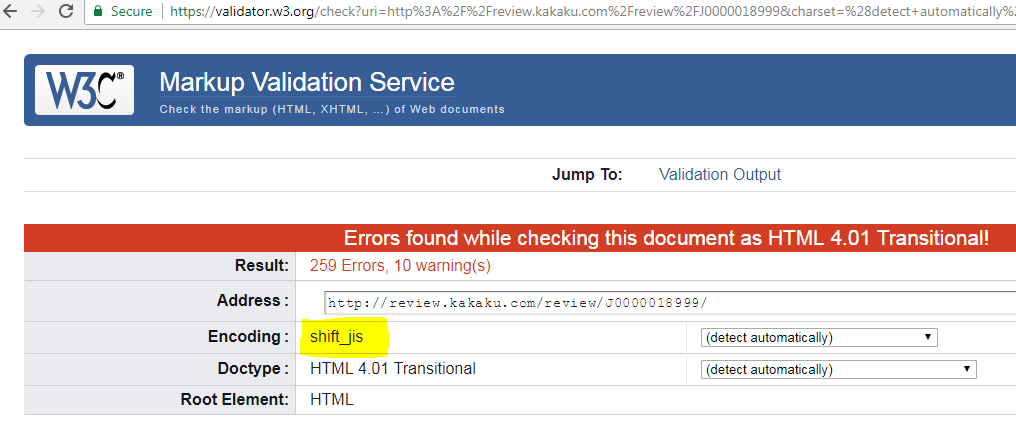
For those cases, we use the W3 Validator, where you can enter the url of the website or just paste the text (website source) to detect the actual encoding used on that language text. For example, if you see the screenshot below, I use the website url and submit to validation, in result the w3 validator detects the shift_js encoding automatically.
So, if you are looking to extract data from Chinese or Japanese websites? - Signup with Agenty