Agenty stores upto 7 to 30 days historical data for web crawling depending on your plans. You can access the historical data on Agenty cloud portal or using our API to pass the job_id parameter.
Using cloud portal
- Login to your Agenty account - https://cloud.agenty.com
- Go to your web scraping agent page
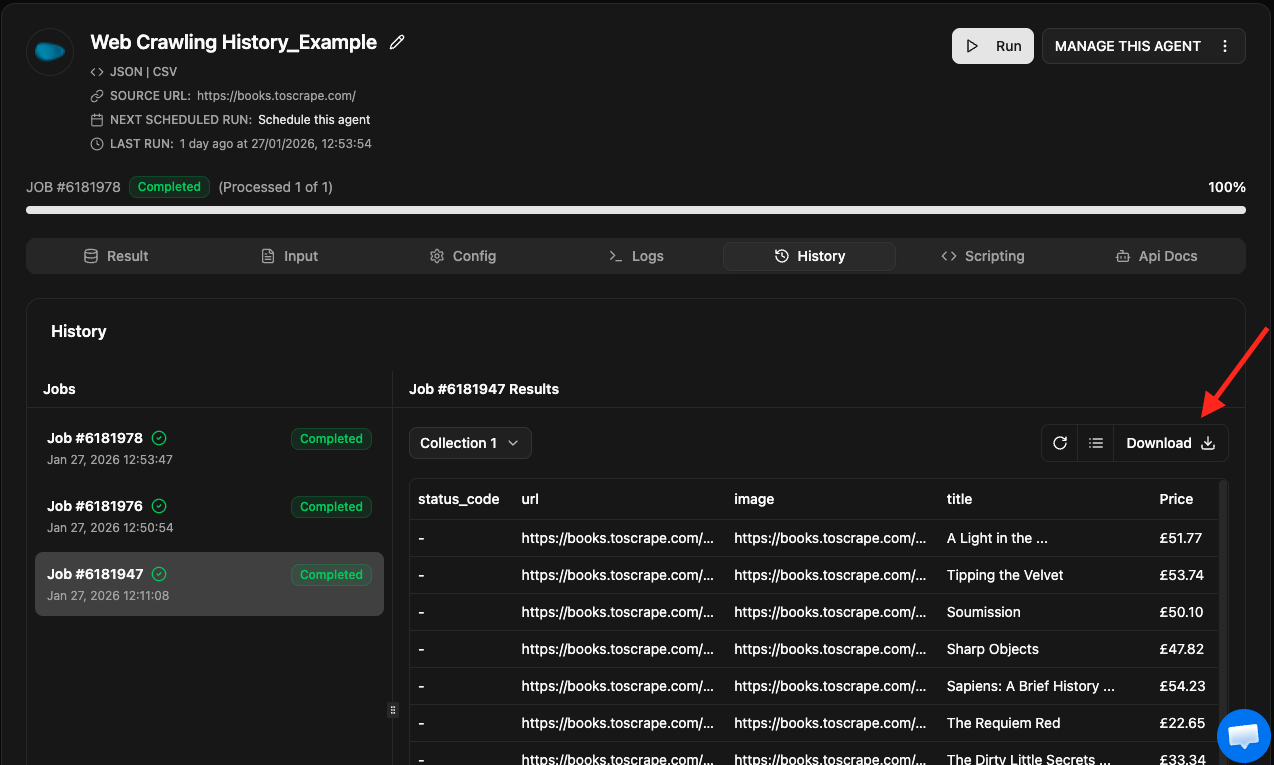
- Then click on the History tab
- Here, you can see the all historical run with
datetimeandjob_idfor selected agent. - Click on the job_id/ date on the left side to load that job result in table. And you may also export the result in CSV, JSON using the download button when the result is loaded in table.
Using API
To download the historical web crawling result via API. First we need to get the job ids from the jobs API, and then send another GET request to export API to generate the download link using that job_id parameter.
Get jobs by agent id
Fetch all the jobs for given agent id.
curl -X GET -H "Content-type: application/json"
'https://api.agenty.com/v1/jobs?agent_id={AGENT_ID_HERE}apikey={API_KEY_HERE}'
Get download link by job id
Generate a CSV download link for given job id.
curl -X GET -H "Content-type: application/json"
'https://api.agenty.com/v1/jobs/{JOB_ID_HERE}/export?apikey={API_KEY_HERE}'
Data retention
Here is data retention time according to plan:
- Basic plan - 7 days data retention
- Professional plan - 15 days data retention
- Business plan - 30 days data retention
- Enterprise plan - Customized as per need
See pricing page for more details - https://www.agenty.com/pricing/