In this tutorial, we will learn how to use Field types in scraping agent. The type attribute specifies the type of element to display. The default type is text. There are 5 way to use this input type.
- CSS
- REGEX
- JSON
- DEFAULT
- INPUT
CSS Field Type
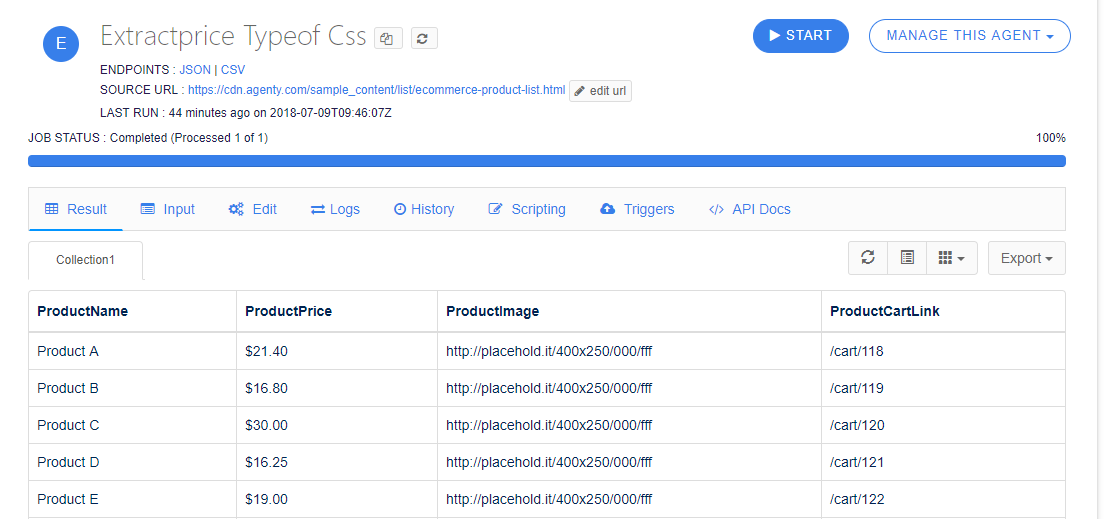
The CSS field type is used to select elements with a specified attribute and value. For example, I have this URL https://cdn.agenty.com/sample_content/list/ecommerce-product-list.html and I want to extract these fields(ProductName, ProductPrice, ProductImage, ProductCartLink).
Steps
- Login your Agenty account
- Extract all these fields(ProductName, ProductPrice, ProductImage, ProductCartLink) as given in screenshot below

-
Save the scraping fields and now you can see your extracted result
, -
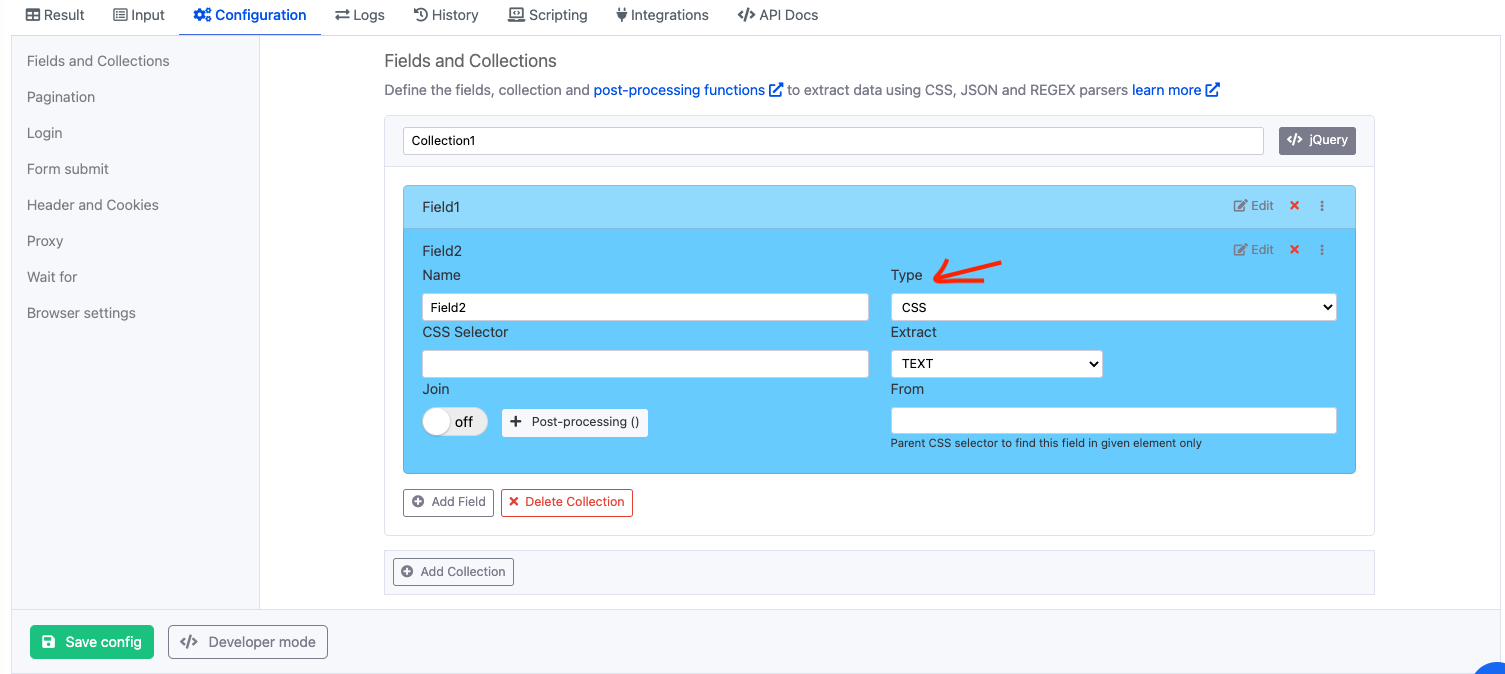
Now if you click on configuration tab and view the Fields and Collections, you will find that the selected field type is
CSS.
REGEX Field Type
To extract data using regular expression(RegEx) is one of the easiest way with web scraping agent. While it’s recommended to use CSS selectors when possible, we cannot deny the fact that sometimes REGEX is required to extract some content which is not part of HTML but it needs to be parsed to get agent result.
For example, some JavaScript variable value inside a script tag.
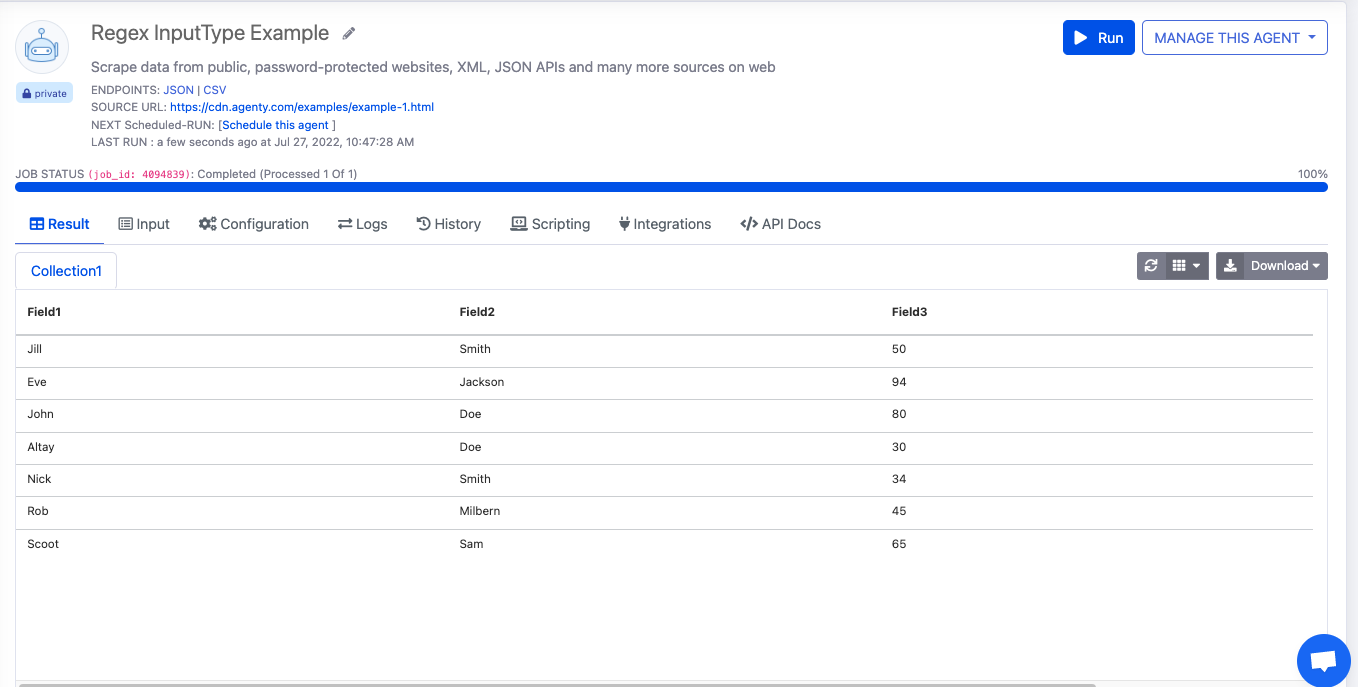
In this example, I will show you how to extract HTML table fields using REGEX type to learn how the REGEX option can be used to extract anything you want from the page content. Here, I am going to use this example page: https://cdn.agenty.com/examples/example-1.html
Steps
-
Create a new web scraping agent using Agenty chrome extension or use a Sample agent.
-
Go to the example page (or the page you want to extract) and open the HTML source code in a editor or using “View source” option in browser
HTML Source :<!DOCTYPE html> <html> <head> <style> table, th, td { border: 1px solid black; border-collapse: collapse; } th, td { padding: 15px; } </style> </head> <body> <h1>HTML Table</h1> <table style="width:60%"> <tbody> <tr> <td>Jill</td> <td>Smith</td> <td>50</td> </tr> <tr> <td>Eve</td> <td>Jackson</td> <td>94</td> </tr> <tr> <td>John</td> <td>Doe</td> <td>80</td> </tr> <tr> <td>Altay</td> <td>Doe</td> <td>30</td> </tr> <tr> <td>Nick</td> <td>Smith</td> <td>34</td> </tr> <tr> <td>Rob</td> <td>Milbern</td> <td>45</td> </tr> <tr> <td>Scoot</td> <td>Sam</td> <td>65</td> </tr> </tbody> </table> </body> </html> -
Now use any REGEX editor tool to write and test your REGEX pattern.Here, I am using rubular.com in this example.
, -
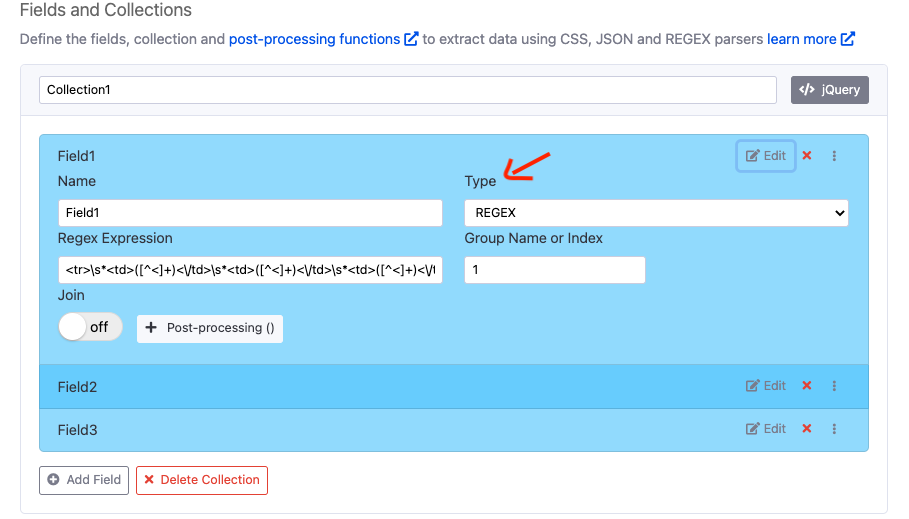
Once we have created our regular expression, click on the Configuration tab to edit the agent and go to Fields and Collections section > select the
REGEXin field type and paste the expression in “REGEX pattern” box.
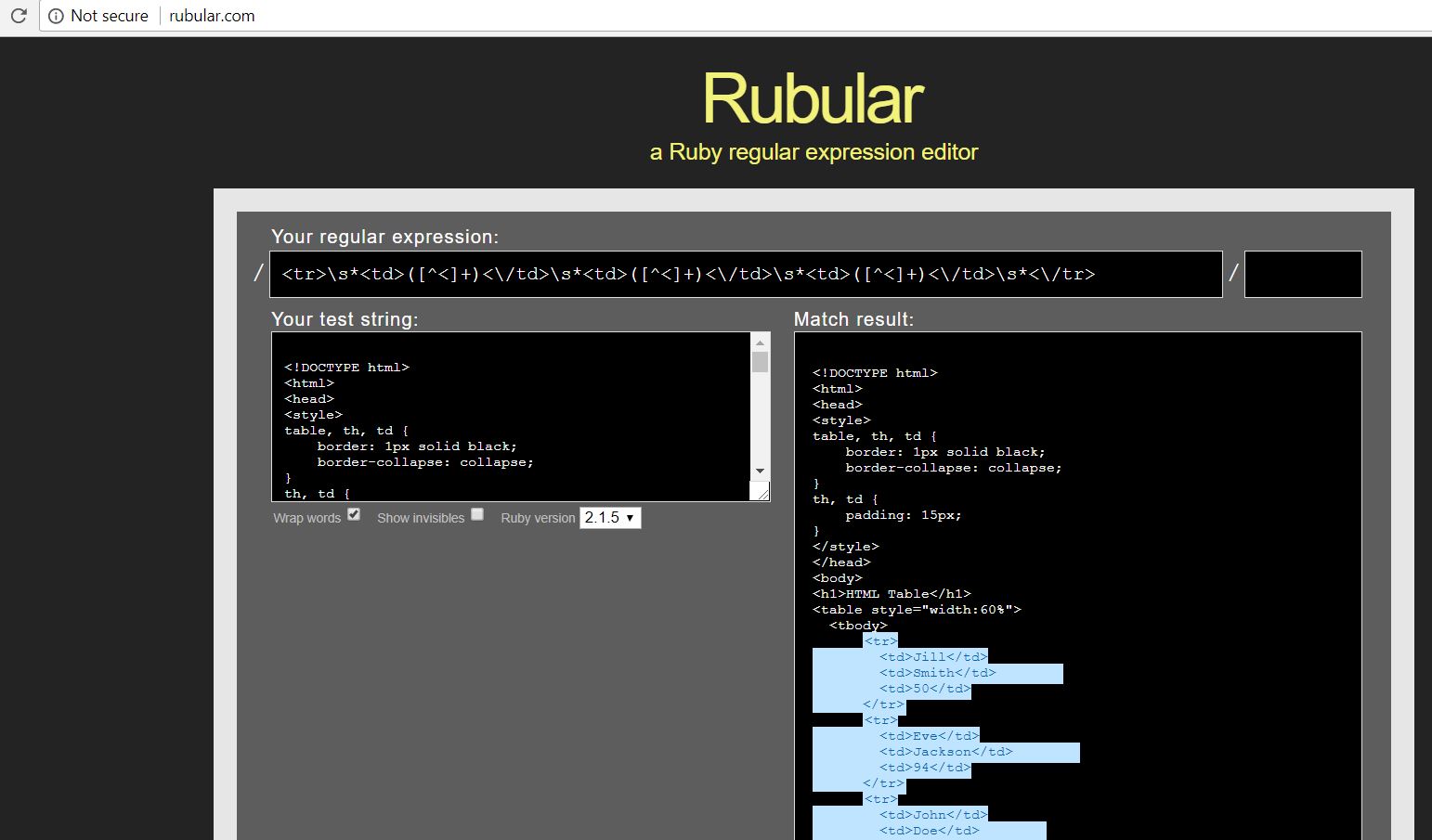
Because the REGEX expression I created is for the entire row (all 3 fields), so I can use the same REGEX expression in all 3 fields by changing the “Group index” to 1, 2 and 3 for the respective field.
- Save the agent configuration and re-run your agent to see the updated result.
DEFAULT Field Type
The Default field type explains itself by the name(default value), this function can be used in the agents to fill any value, where we want to set the field value as a default. As we know, We can extract all data through Agenty’s CSS selector, regex and json scraper engine, but many times businesses required to add some fields in output result that is not available on web page such as timestamp(time of crawling), URL( source URL of web page), status(HTTP status of successful request) and most important part screenshots(to test or diagnose the web data) and lots more… So, this Default field option help out us to add more value in output result that is not available on web page and diagnose the scraping result.
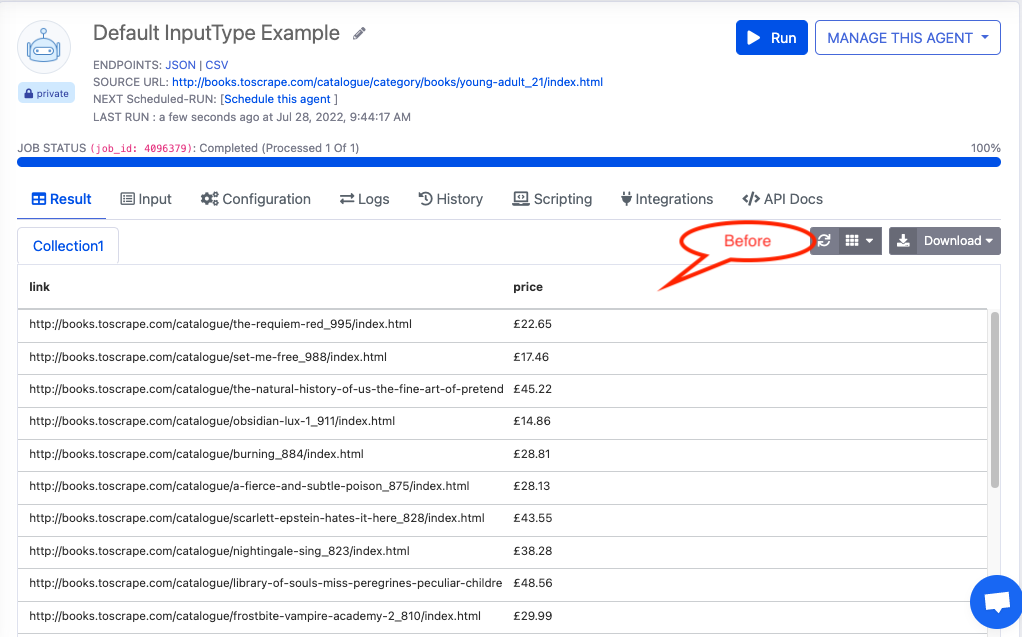
Before DEFAULT Field Type
For example, We have the scraping agent “Default InputType Example” and we want to check HTTP status code of successful web request, for eg. OK(200), moved permanently(301), bad request(400) etc…
In this example, we will add new default field status in this scraping agent. So, let’s know how to add and use default field type in web scraping agent.
Steps
- Edit the scraping agent by clicking on the Configuration tab > go to Fields and Collections section.
- Add a field name it as I gave “status_code”
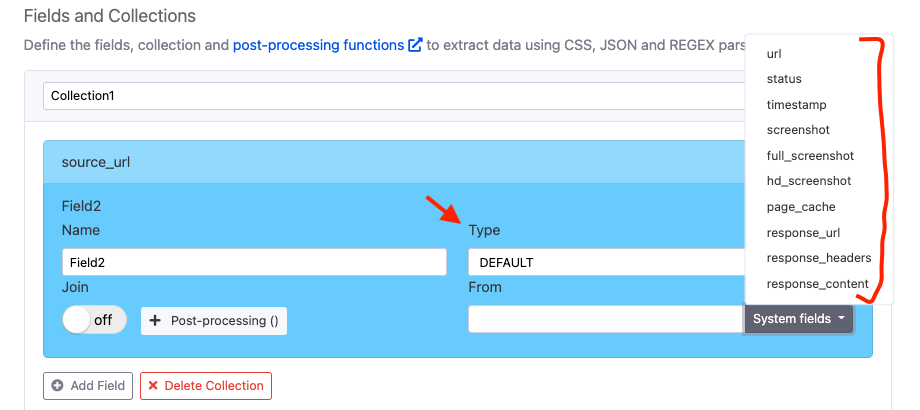
- Add Default in Type section
- Select status from System fields dropdown
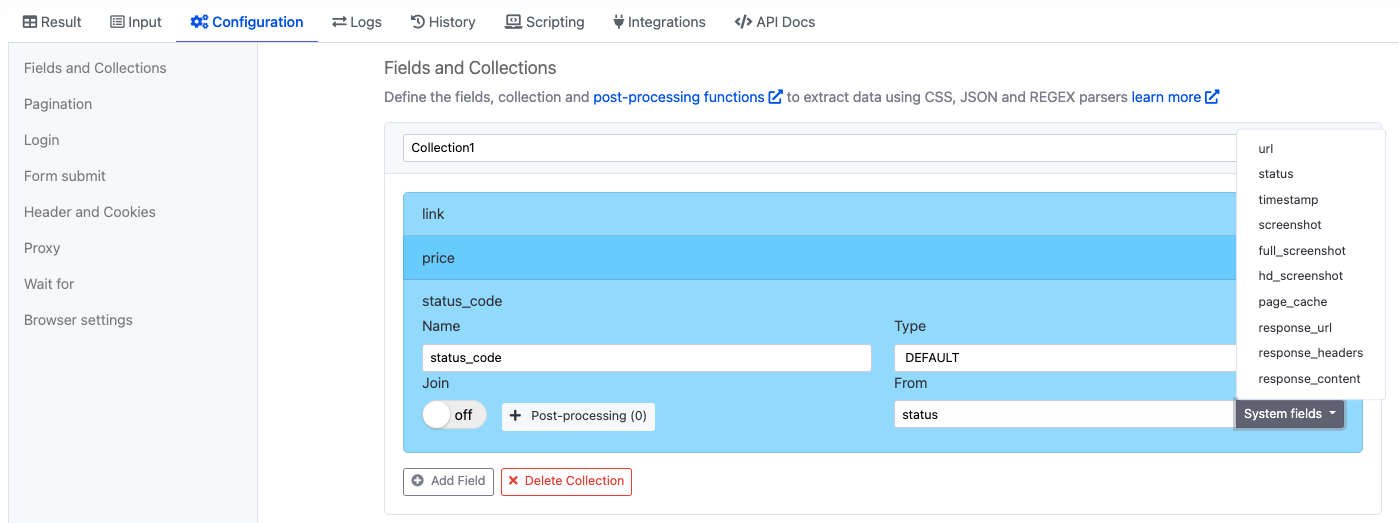
- Just save the scraping agent configuration
- And start your agent to see the updated result.
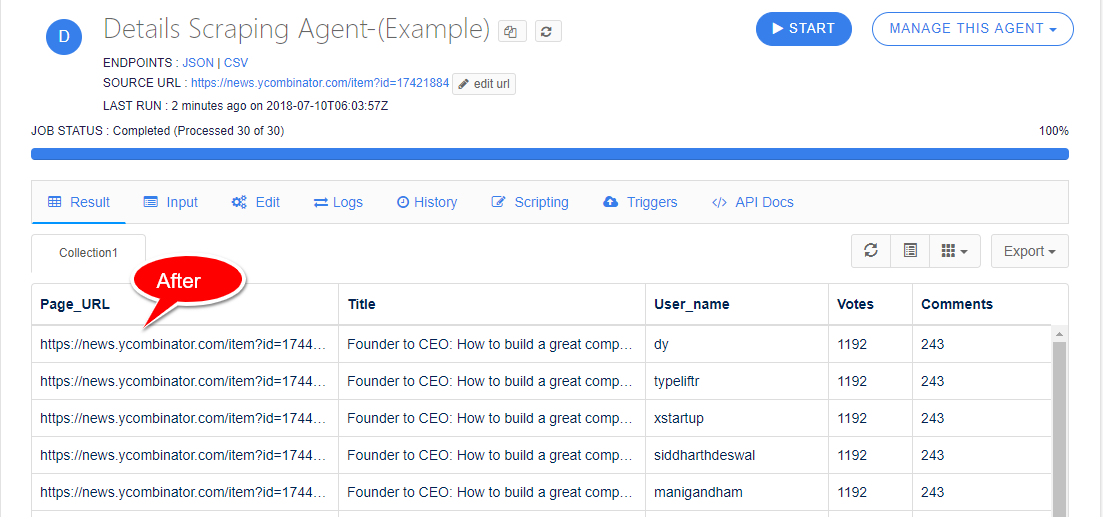
After Default Field Type
If you notice the screenshot below, the status_code field is added to the agent and http status code is shown in output result by DEFAULT input type.

INPUT Field Type
The input field type are used to pull a field value from selected input file. The selected input file may be a list, or another scraping agent.
Steps
-
We create two agents first one is List Scraping Agent-(Example) which consists two fields(Website_URL, Page_URL) and second is Details Scraping Agent-(Example) which consists 4 fields(Title, User_name, Votes, Comments)(Note: To create an List Scraping Agent and Details scraping agent please see the connecting Agents Documentation)
, , -
Edit Details Scraping Agent by clicking on the
Edittab and go to Fields and Collections section -
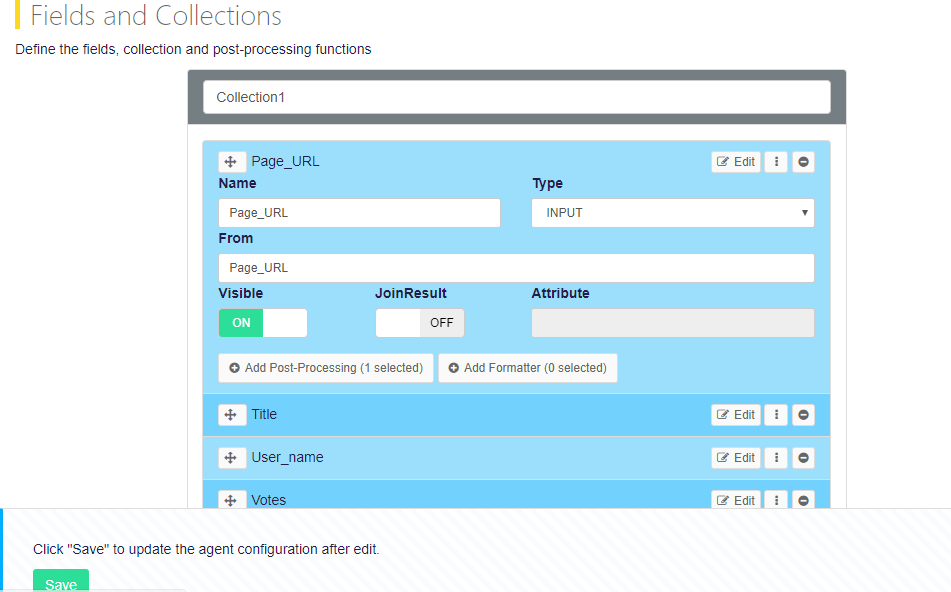
Click on
Add Fieldbutton and add a field Page-_URL and then Edit it -
Now select the
,Typeas INPUT because that field is dependent on the parent agent and selectFrominput field same as Name input field like we given Page_URL, as in given screenshot below
-
Now Add the function
AutoFillBlankCellin Page_URL field 6 Save the scraping agent configuration and re-run your agent to see the updated result.
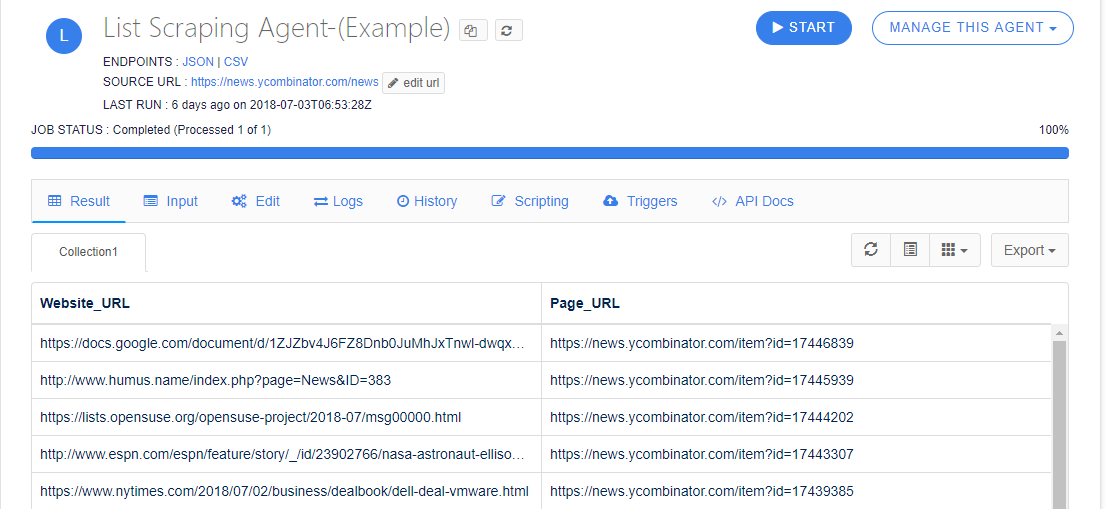
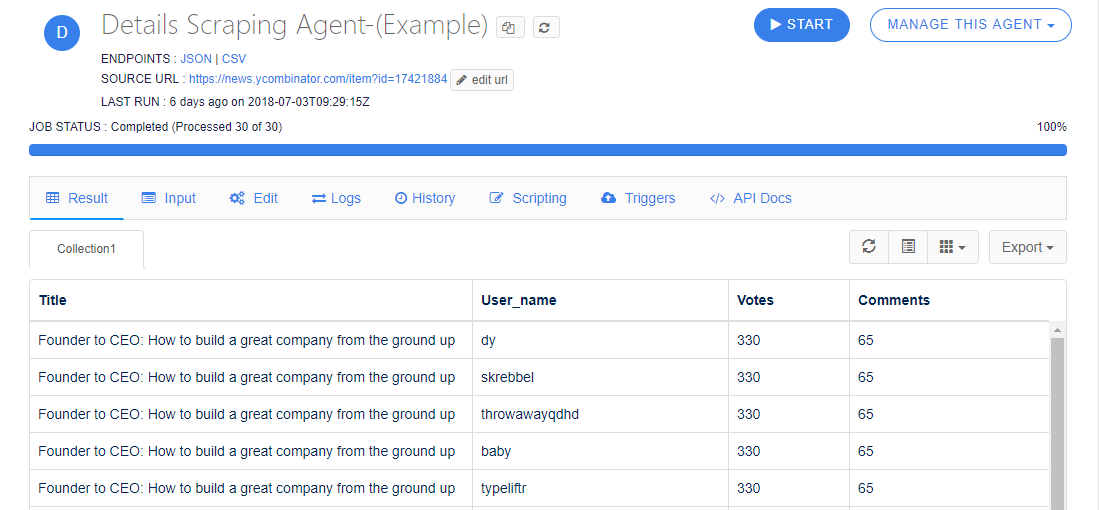
After INPUT Field Type
If you notice the screenshot below, you will find the extracted field.
,