In this tutorial, we will learn how to crawl a password protected website online by passing the username, password in agent configuration for authentication programmatically and then crawl the behind login webpages.
To crawl a website with login, first of all we must get authenticated our scraping agent with Username and Password. And then, we can scrape the internal pages as we do with public websites. Scraping the web with Agenty, hosted app is pretty easy and quick to setup using the extension and then we can enter the credentials by editing the scraper in agent editor. This tutorial shows how to get data from a password protected website after login successfully and then schedule the scraper to scrape the website with login automatically on scheduled time.
https://www.youtube.com/watch?v=z6TWq9Fyh6I
There are 2 types of authentications:
- Form Authentication
- Http Authentication (also called as Basic or Network Authentication)
Form Authentication
Form-based authentication is the most widely used website protection technique, where the websites display a HTML web form to fill in the username, password and click on submit button in order to login and access the secure pages or service. A usual password protected website scraping with form-authentication workflow looks like below and we need to perform all steps one by one to get data from a website that requires a login.
-
Navigateto the login page. - Enter the
Usernamein input field - Enter the
Passwordin input field - Click on the
Loginbutton - Start scraping internal pages.
Commands
The form-authentication engine in scraping agent has the following commands to interact with a login page using CSS Selectors as the target of any element, this will allow us to complete the initial 1-4 login steps prior to start scraping internal pages.
Navigate
To navigate a particular webpage, for example the login page for authentication
Required Parameters:
- Value: A valid URL to navigate.
Type
To type some text in a text box. For example, username or password to the text box
Required Parameters:
- Target: A valid CSS selector of text box.
- Value: Value to enter in the text box.
Click
To click on a button or a hyper-link
Required Parameters:
- Target: A valid CSS selector of button/link needs to be clicked
Wait
To wait (n) seconds before firing the next event
Required Parameters:
- Value: Seconds(n) to wait
Select
Select an item from dropdown list
Required Parameters:
- Target: A valid CSS selector of dropdown box.
- Value: Value needs to be selected.
Clear
To clear a text box
Required Parameters:
- Target: A valid CSS selector of text box, drop down to clear.
JavaScript
To inject a JavaScript function
Required Parameters:
- Value: A valid
JavaScriptfunction
Submit
To submit a form (or to press the Enter key)
How to crawl a website with login
Follow these steps to scrape data behind a login :
- Choose any Sample Agent
- Click on the Config tab
- Go to the Login > enable the login as in the screenshot below.

Now go to the website you want to login, and check the web page source to analyse the login form. For this tutorial, I’m going to use the demo login website to demonstrate. So there will be the 5 steps I will add in my agent to login successfully:
-
Navigate the login site Type: Navigate Target: Value: https://sandbox.moodledemo.net/login/index.php
-
Add username Type: Type Target: #username(CSS selector) Value: admin (admin@domain.com)
-
Add password Type: Type Target: #password(CSS selector) Value: sandbox(add password)
-
To click on
loginbutton Type: Click Target: #loginbtn(CSS selector) Value: -
Add wait (in milisecond) Type: Wait Target: Value: 200ms (as per requirement)
The target CSS selector can be written with name, class or id. For example, to click on the “Sign In” button all these selectors are valid.
#ContentPlaceHolder1_LoginPanel_Password.StandardButtoninput[type='submit']

Once the login configuration part has been completed, save the scraping agent, and scroll up to the main agent page to start and test your agent. It’s always a best practice to test with few URLs to ensure that the agent is login successfully before running a large job. For example, I entered some internal URLs in input which was accessible after login only, and then started the scraping job.
Agenty recommends to run a test job for a few URLs, when the agent configuration has been changed. As that will allow me to analyze the result to ensure everything is working as expected, instead of starting the agent for a big list of URLs.
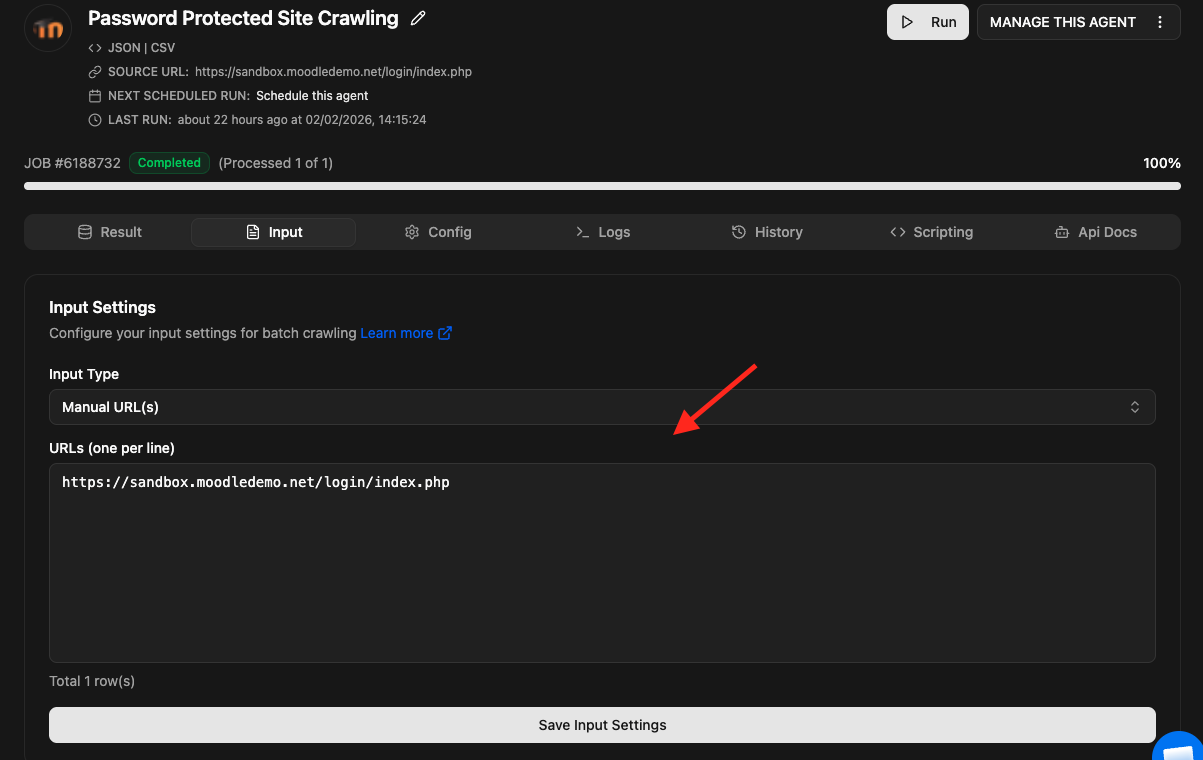
Then click on the Run button to start the web scraping agent job.
Logs
2023-03-21T06:13:06.268Z INFO Worker id: 370
2023-03-21T06:13:06.295Z INFO Job: {"job_id":4397124,"account_id":28535,"agent_id":"4mmgee6yke","type":"scraping","status":"started","priority":1,"pages_total":0,"pages_processed":0,"pages_succeeded":0,"pages_failed":0,"pages_credit":0,"created_at":"2023-03-21T06:13:06.235255Z","is_scheduled":false,"running_process_id":7379,"running_worker_id":370}
2023-03-21T06:13:06.392Z INFO Input type: url
2023-03-21T06:13:06.410Z INFO Job id: 4397124, Type: scraping, Status: running
2023-03-21T06:13:06.410Z INFO Total inputs: 1
2023-03-21T06:13:06.470Z INFO Login: 5 actions
2023-03-21T06:13:06.470Z INFO Running action 1 of 5
2023-03-21T06:13:06.470Z INFO Navigate to https://sandbox.moodledemo.net/login/index.php
2023-03-21T06:13:10.145Z INFO Running action 2 of 5
2023-03-21T06:13:10.145Z INFO Type admin on #username
2023-03-21T06:13:10.213Z INFO Running action 3 of 5
2023-03-21T06:13:10.213Z INFO Type sandbox on #password
2023-03-21T06:13:10.298Z INFO Running action 4 of 5
2023-03-21T06:13:10.298Z INFO Click on #loginbtn
2023-03-21T06:13:13.912Z INFO Running action 5 of 5
2023-03-21T06:13:13.912Z INFO Waiting 2000 ms
2023-03-21T06:13:15.928Z INFO Running page 1 of 1
2023-03-21T06:13:15.928Z INFO https://sandbox.moodledemo.net/user/index.php?id=1
2023-03-21T06:13:16.788Z INFO Status: 200
Result
It will take a few seconds to initialize and login, then the web scraping agent will start scraping internal pages, and we can see the progress, logs and the final result as per your fields selection in the result output table.

Basic Authentication with FORM
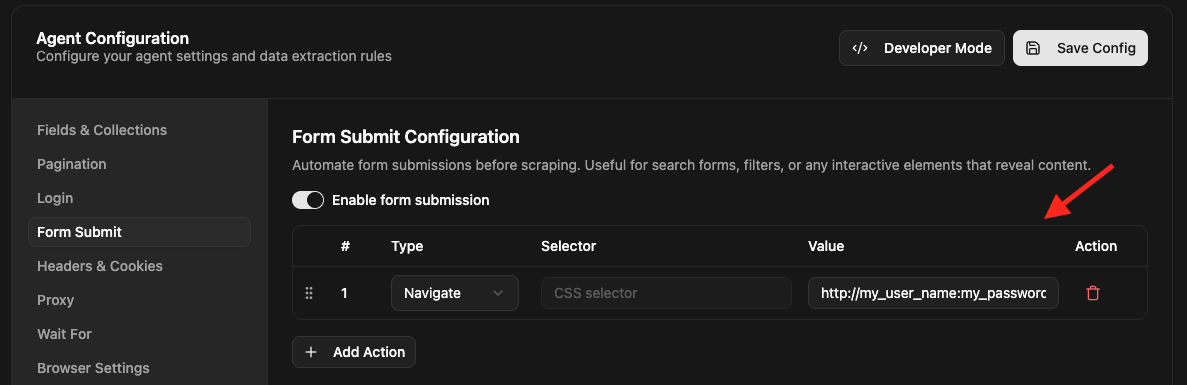
We can also get our agent session authenticated by sending a Navigate request with username and password in the URL itself. Just make a first request using form authentication or Form submit feature with URL format below:
http://<user>:<password>@<host>
For example :
http://my_user_name:my_password@domain.com
Notes
- When crawling password protected websites, we recommend to spend some time in analysis first, and try to use the specific login page of the website instead of a dialog box or popup login when possible. You may find that by logging in and then logging out, most of the website auto-redirect users on specific login page when logged out.
- Add a 5-10 seconds of wait after clicking on the “Login” button to give enough time to the website for auto redirection to the main or home page.
- If the website requires AJAX, JavaScript? Go to the
Enginesection and then enable JavaScript with theDefaultengine selected.
Recommendation: Use theFastBrowserengine, if the target website doesn’t require JavaScript or images to be loaded for login and also to render internal pages you are crawling.
Want to extract data behind login? Let the Agenty team setup, execute and maintain your data scraping project - Request a quote