The download feature in Agenty allow you to download the product images, pdf, screenshot or other documents from the web using the data scraping agent, and then upload them to your S3 bucket automatically. Let’s see how to download images, multiple files and pdf to s3 bucket.
Now, all paid customers can extract pdf, images and documents. And download them to their S3 bucket with all the web data extracted in CSV, JSON format.
Prerequisites
- A S3 bucket in any region.
- A scraping agent with any field has a valid hyperlink of image, pdf, screenshot, swf etc. to download the file from.
For example, I have this scraping agent with column ProductImage - Which is a valid image scraped using the SRC attribute and can be downloaded from this image URL.
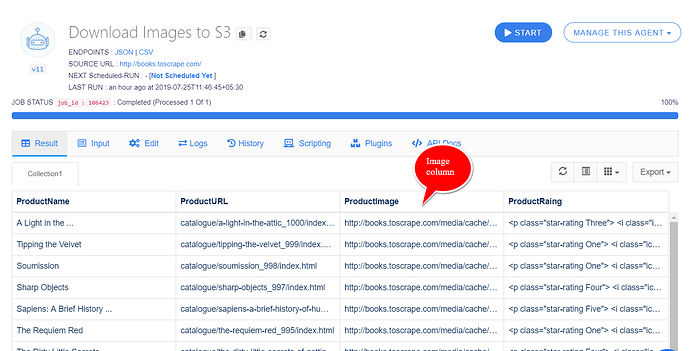
See this article to learn how to scrape images from websites
Download options
- Click on the edit tab to change the agent setting
- Scroll down to the field which has the file to download
- Click on the add post processing function button
- Select the
DownloadToS3function and enter your S3 details as in this screenshot
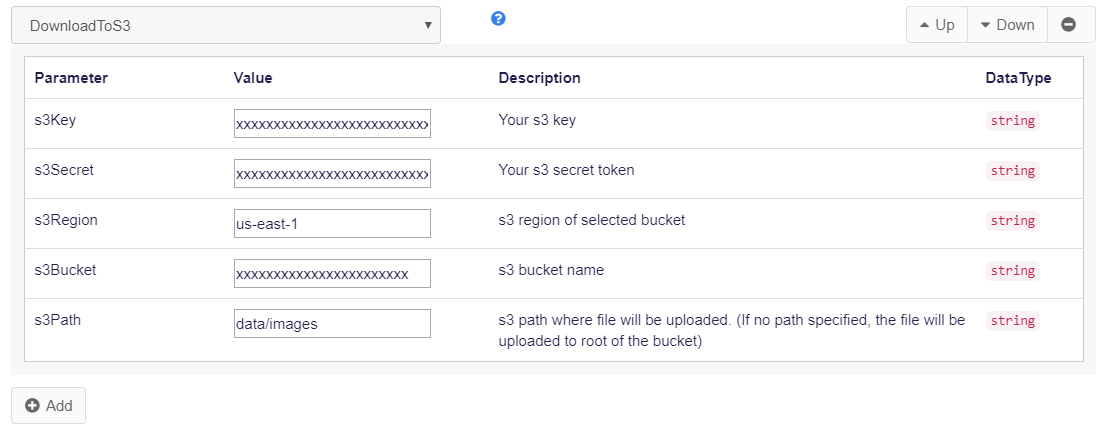
Note : The download URL must be a valid(full) HTTP or HTTPS URL with domain, instead the relative path of file. If it’s relative to the website you are scraping? you may use the insert function to convert relative URL into full URL by adding the domain before the Download function.
Now run your scraping agent and it will download the images automatically to your S3 bucket while the web scraping job is running on a cloud server.
Logs
Click on the Logs tab on your agent page, and you will see the complete trace logs with details about the image(or file) downloaded, what it’s named and where it is downloaded in your S3 bucket.
2019-07-25 13:05:15.9668 TRACE Download success - url: http://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg; name: 2cdad67c44b002e7ead0cc35693c0e8b.jpg; s3path: data/images/2cdad67c44b002e7ead0cc35693c0e8b.jpg`
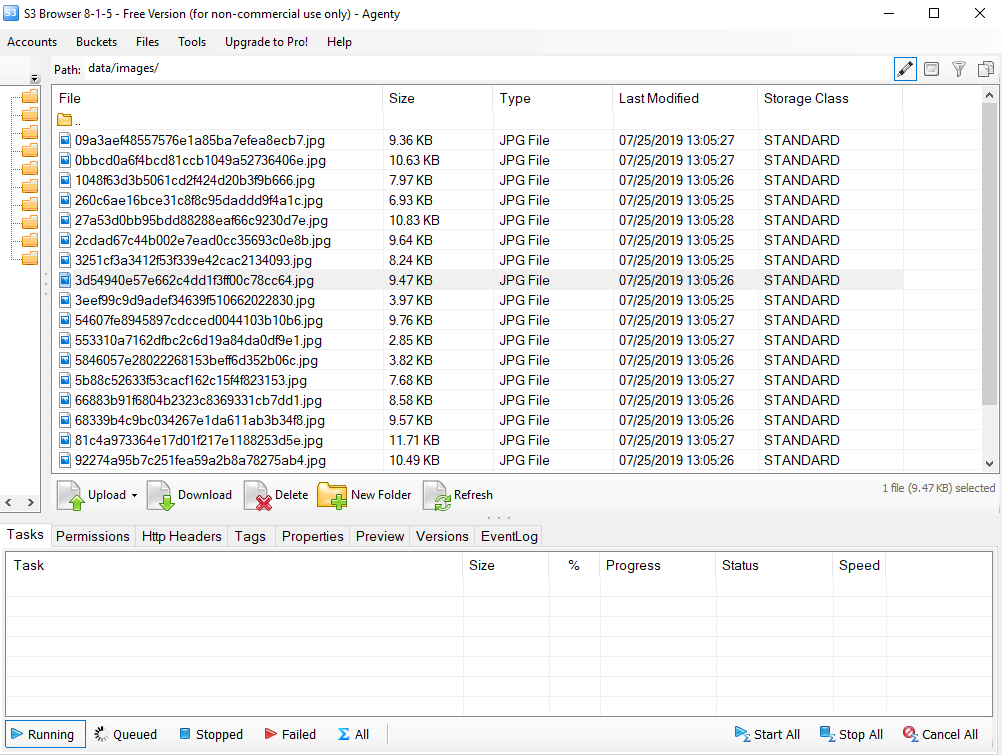
Result
To check your images downloaded, you may login to your S3 account and go to the bucket > path to find all images.
As I am using the free S3 browser software in this screenshot to view my images, and we can also bulk download these images(or files) to our local computer directory using the Download option and then selecting the folder.
Additional parameters
- You may also use the dynamic parameters to download your files on a dynamically generated path on S3. For example, if you want to download the images on
job_idfolder insidedata/images/. You may use the dynamic parameters to generate the path run time as in documentation here - So using the
data/images/{{job_id}}/in s3Path variable will modify the{{job_id}}with106423as that’s the unique job id for this scraping job.