Agenty’s scraping agents are easy and powerful no-code website scraping tools. Using the scraping agent, you can create your web scraper online and run it on Agenty web scraping software on cloud (or via our API) to scrape the data from thousands of websites online without code.
In this article, we will go over the basics of web scraping and then walk you through building a no-code web scraper using Agenty’s Chrome extension to get the data from the webpage into excel spreadsheet format.
If you don’t have the extension already? - Install it from Chrome store
https://www.youtube.com/watch?v=Ov1nva1XmCg
Once the advanced web scraper Chrome extension is installed, go to the web page you want to scrape the data from. Then, launch the extension by clicking on the robot icon on the top right side. It will display a panel on the right side as in this screenshot.
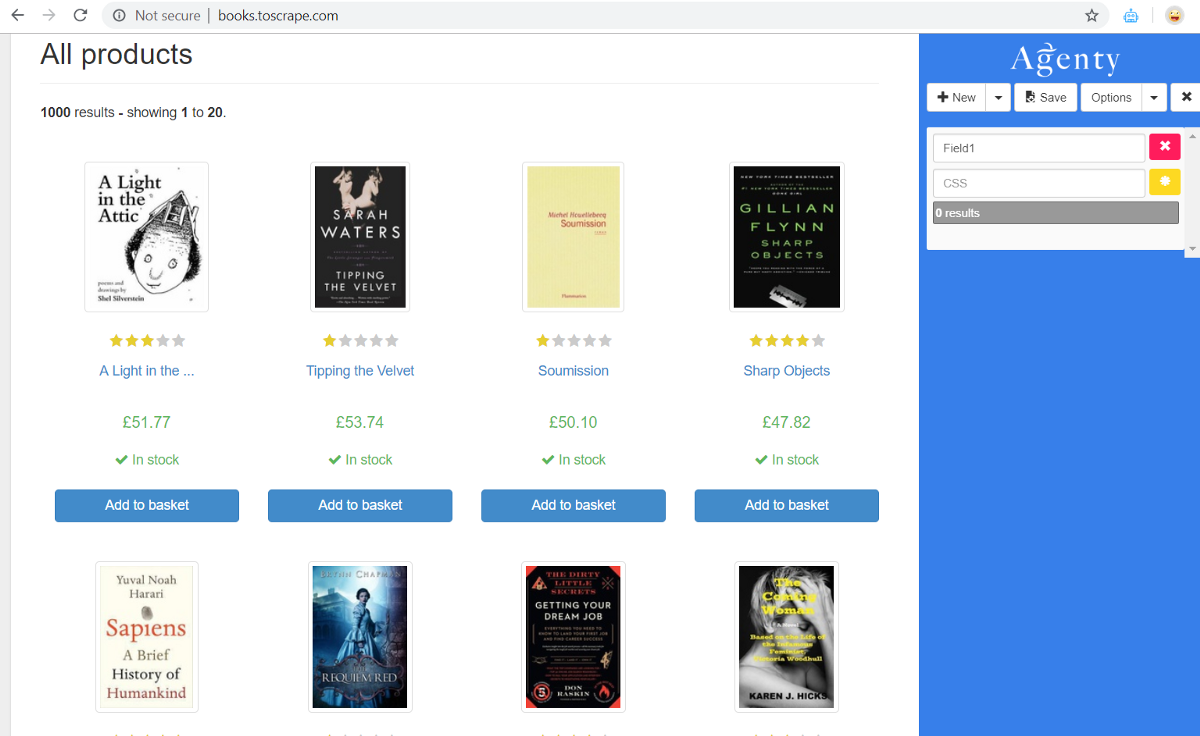
Text Scraping
Once the extension panel is up and visible -
- Click on the
Newbutton to add a field and give a name to your field as I did and named itProductName. - Then click on the
(asterisk)button to enable the point-and-click feature to easily generate automatic CSS selectors when you click on the HTML element you want to scrape. For example, I want to scrape the name of products in this field. So, I clicked on the product name element on HTML, and the extension automatically generated the selector for that element and highlighted the other matching products with the same selector on this page.
Sometimes you may see other matching items might be selected, due to the same CSS class or selector — So you can click on the yellow highlighted items to reject them or can also write your selector manually by learning from here.
The extension will highlight the matching result, and will also show you the result preview under the field. Once you are satisfied with the result and the number of records looks per your expectation, click on the Accept button to save that field in your scraping agent configuration.
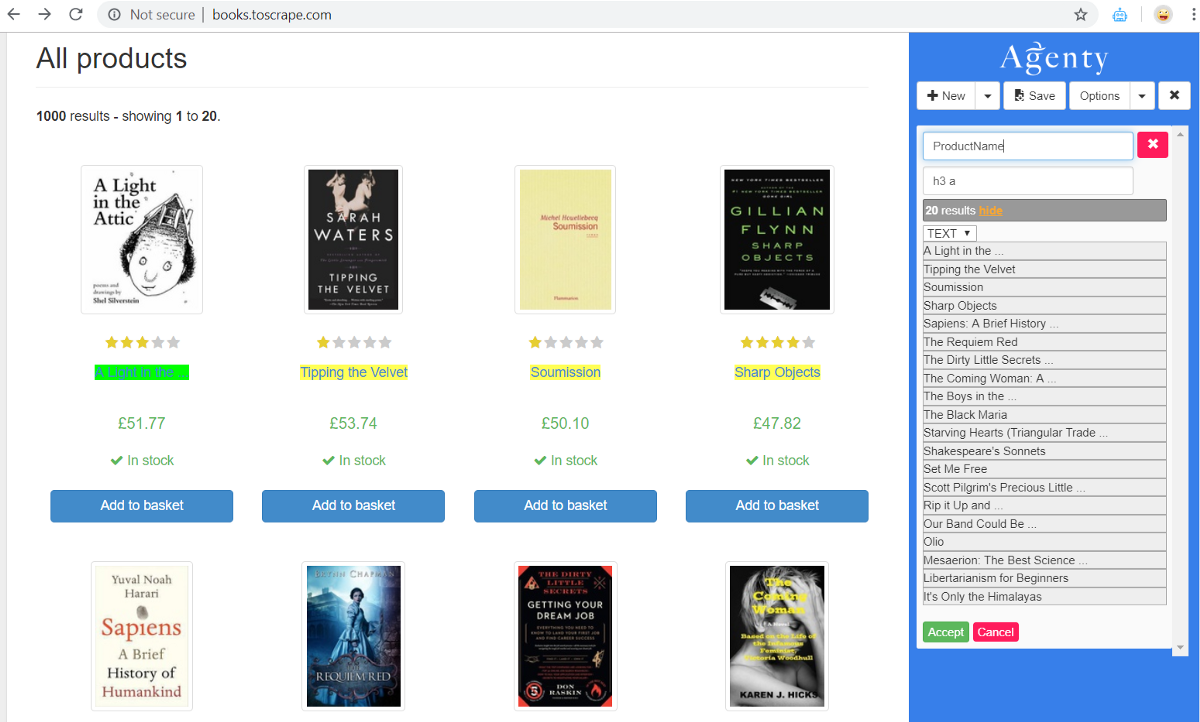
Now, follow the same process, to add as many fields as you want for Text, Attribute or HTML items to scrape anything from the html pages.
Hyperlinks Scraping
To scrape URL hyperlinks from websites, we need to extract the href attribute value, so after generating the CSS selector of hyperlink a element —
- Select the the ATTR option in extract type
- Enter href in the name of attribute box, to tell Agenty that you want to extract the value of href in output instead of plain text or HTML.
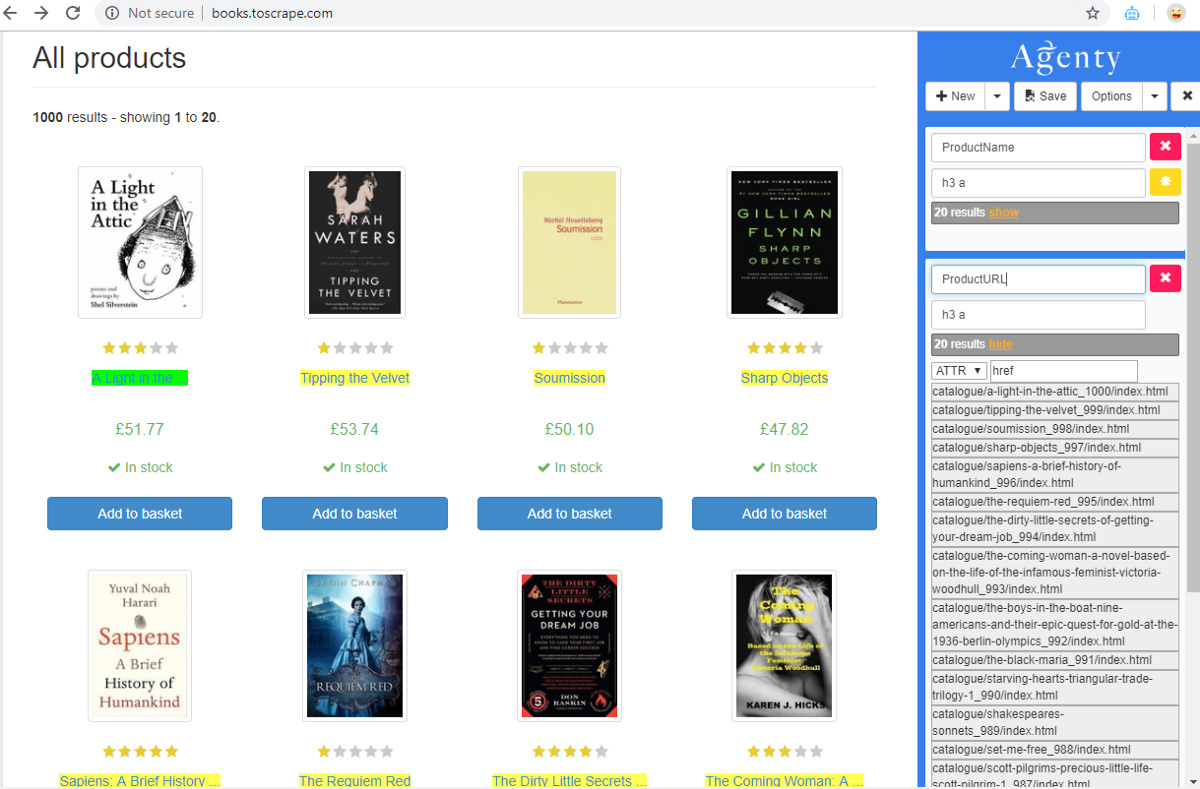
Images Scraping
To scrape images from websites, we need to extract the src attribute value, so after generating the CSS selector of image element —
- Select the ATTR option in extract type
- Enter src in the attribute text box, to tell Agenty that you want to extract the value of src in output for images scraping.

HTML Scraping
If you are looking to scrape the full HTML tag instead of the plain text or some attributes from the element.
- Write your own selector
- Select the extract type as : HTML
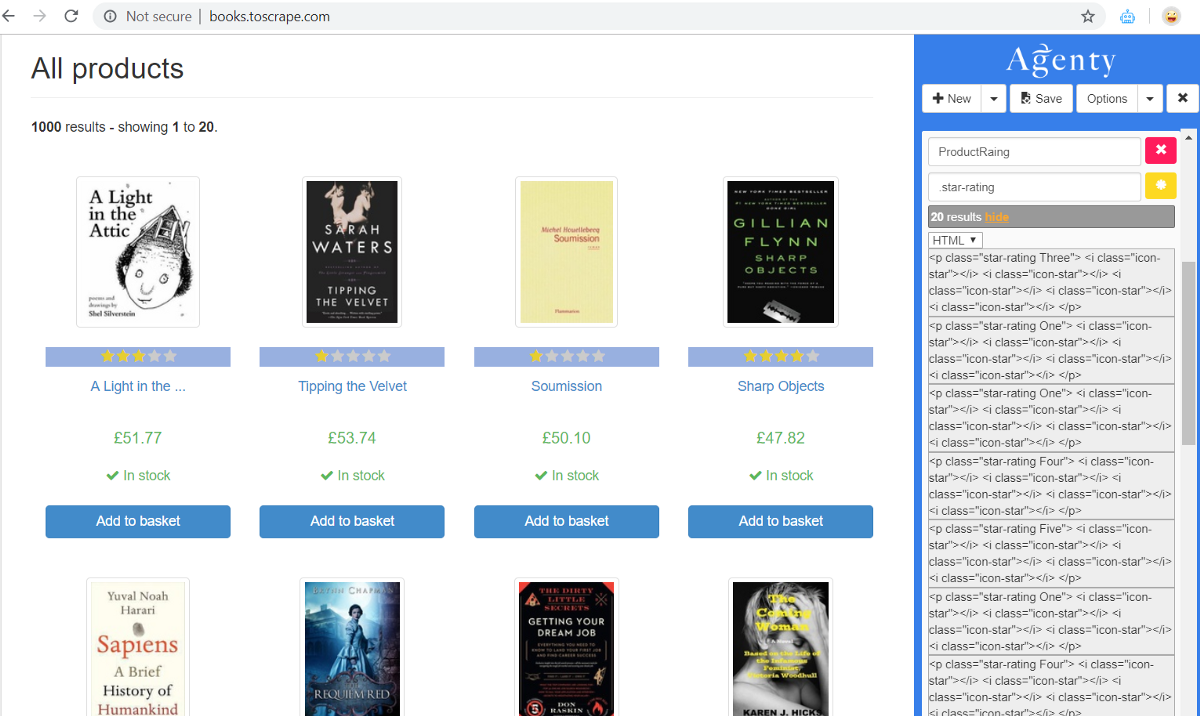
Attribute Scraping
The ATTR (attribute) option in scraping agent is a very powerful feature to extract any attribute from a HTML element. For example —
- We used src attribute for images scraping
- And href attribute for URL scraping
- Similarly, we can extract HTML data-* attributes, class, id or any other attribute given in HTML to add in our web scraping data
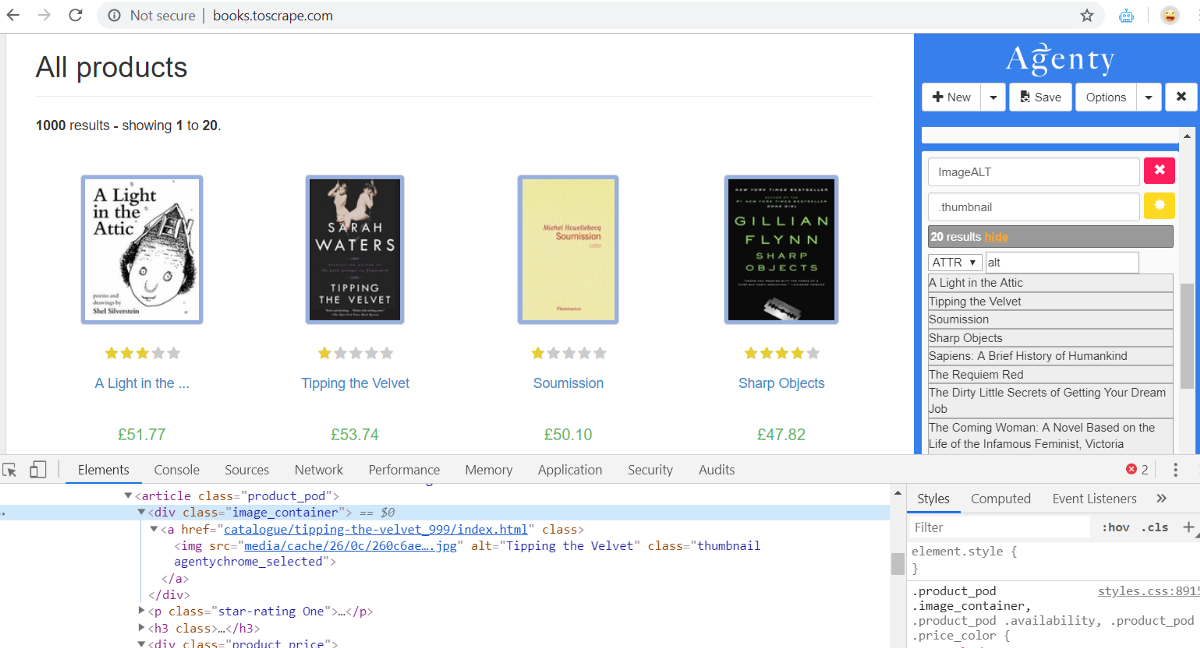
<div class="image_container">
<a href="catalogue/tipping-the-velvet_999/index.html">
<img src="media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg" alt="Tipping the Velvet" class="thumbnail">
</a>
</div>
As I scraped ALT attribute in this example HTML page, and named the field : ImageALT
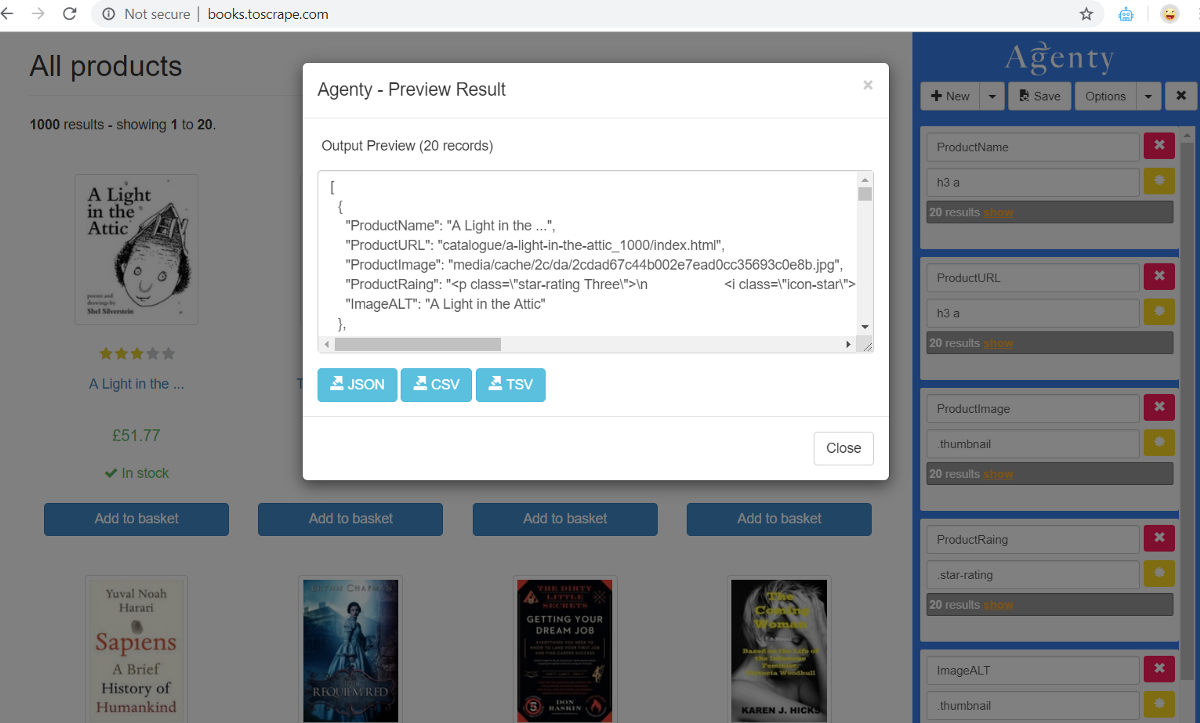
Preview Result
You may preview or download the scraped data in JSON, CSV or TSV formats on extension itself -
- Click on the Options drop-down button
- Then the Preview result option will open a dialog box with all the fields result combined in the JSON array of objects.
Save the Agent
Once you are done with setting up all the fields in your agent, click on the Save button to save your web scraper in your Agenty account.
if you are using the extension first time — The extension will ask you to sign-in on your account before you can save the agent. So, create your free Agenty account or enter the credentials to login.
Remember — The Chrome Extension is used to set up the fields of scraper initially, for a particular website scraping. After that, the agent should be stored in your Agenty account for advance features like scheduling, batch crawling, connecting multiple agents, plugins etc.
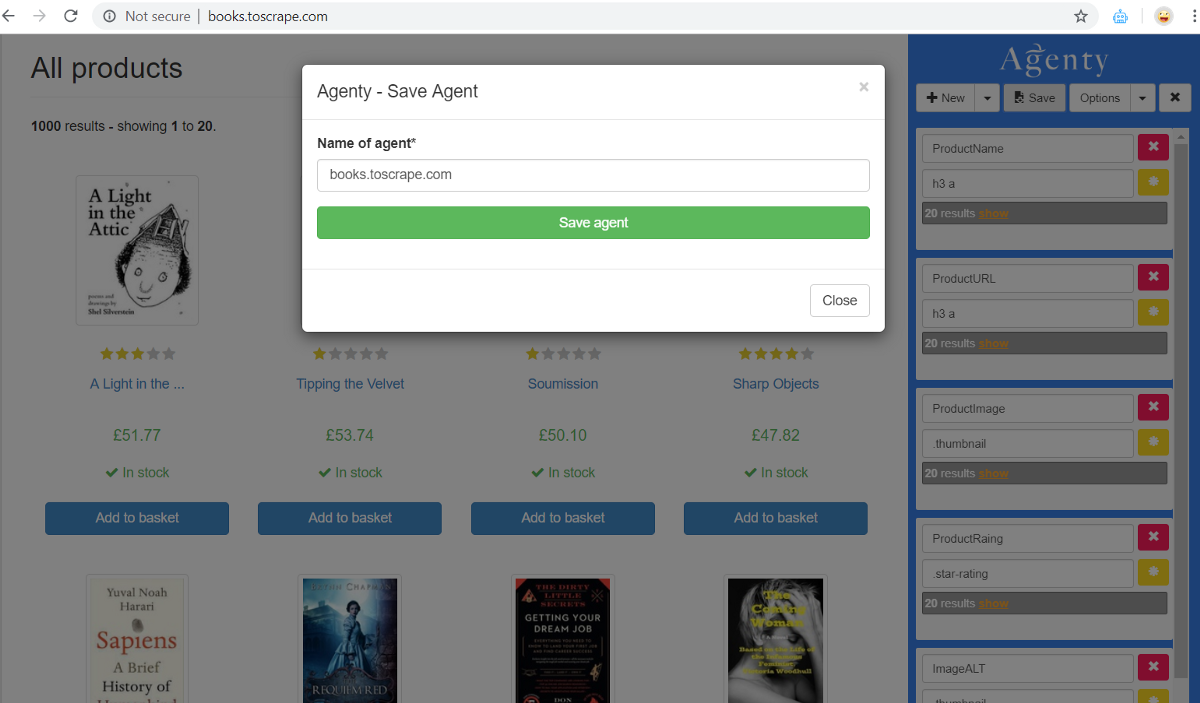
Once the agent is saved in your account, it will looks like this:
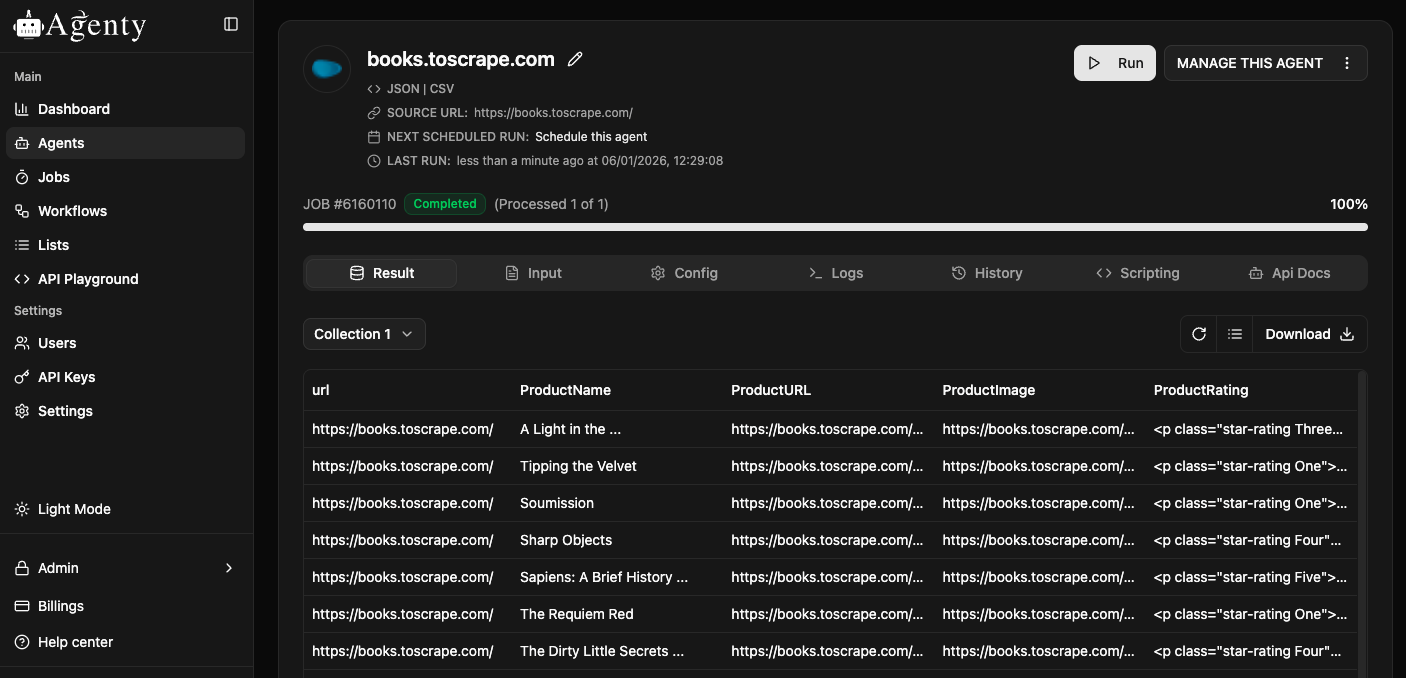
Now, no need to go back to Chrome extension ever for instant data scraping, you may simply click on Start button to start the web scraping task on-demand or can use our API to run it from programming language like Python, Perl, Ruby, Java, PHP or C#…etc.
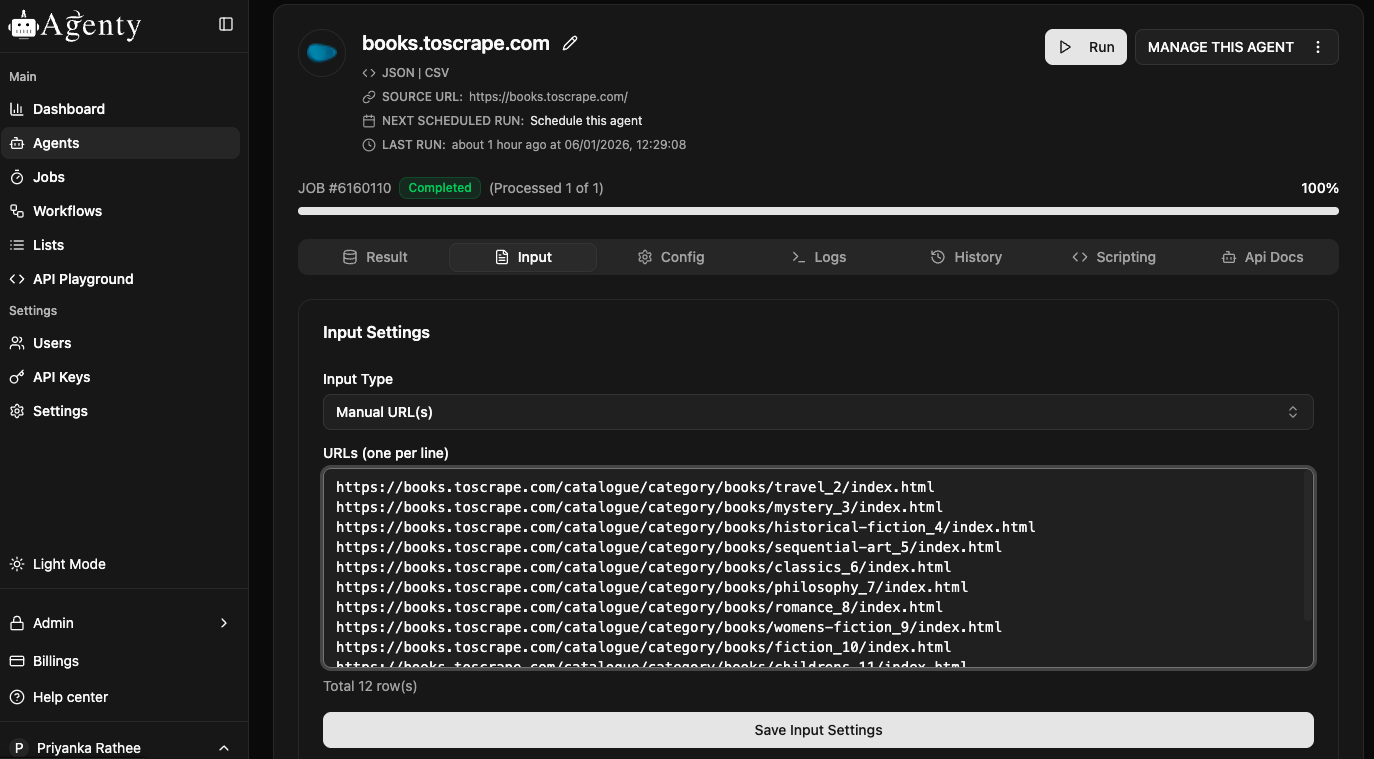
Crawl More Pages
The scraping agent can be used to crawl any number of similar structure web-pages. All you need to do is enter the URLs in input for batch crawling or you may use the Lists feature to upload the file and select that in your agent input.
- Go to the input tab
- Select input type as Manual URLs
- Enter the URLs and Save the input configuration
- Now start the agent to crawl all web-pages.