Most of the data scientists often finds themselves looking for external data sources, that could be used to feed their machine learning algorithms. Because finding the open-source data to use for every projects is not easy, or not free, or not updated.
So, having a point-and-click web scraping tool in your list gives the great advantage to collect any data from websites of choice, and then use that data in your machine learning or artificial intelligence projects quickly.
Prerequisites:
- Chrome extension : https://chrome.google.com/webstore/detail/agenty-advanced-web-scrap/gpolcofcjjiooogejfbaamdgmgfehgff
Chrome Extension:
- Install this freeware Chrome extension by Agenty from Chrome store.
- Then go to the URL of website you wants to scrape and launch the extension, in this article I will use : http://books.toscrape.com/
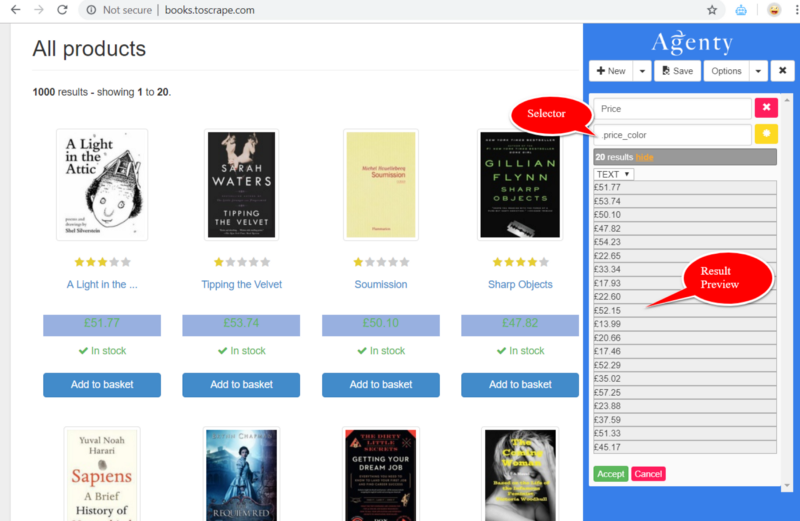
- Click on the “New” button to add a field
- Then click on the yellow “*” button to enable the point-and-click CSS selector generator
- Now click anywhere on the web page to generate the selector and preview the result instantly, as in this screenshot.
Add as many fields you want, for example I added 5 fields in my scraper:
- price
- product_name
- product_url
- product_image
- stock_availability
Attribute Scraping
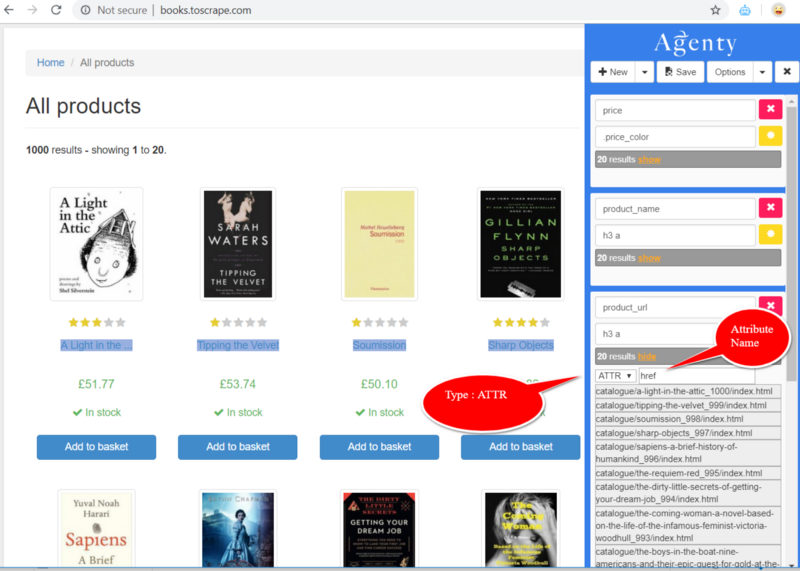
In most cases, we do scrape text from HTML elements. But we can also extract some attribute as well, for example — in this case href for product_url and src attribute for product_image to extract the URL of product and the image path.
All we need to do is, select the ATTR option in extract mode and then give the name of attribute in next box to tell Agenty what attribute we want to extract from the HTML element.
Result Preview and Export
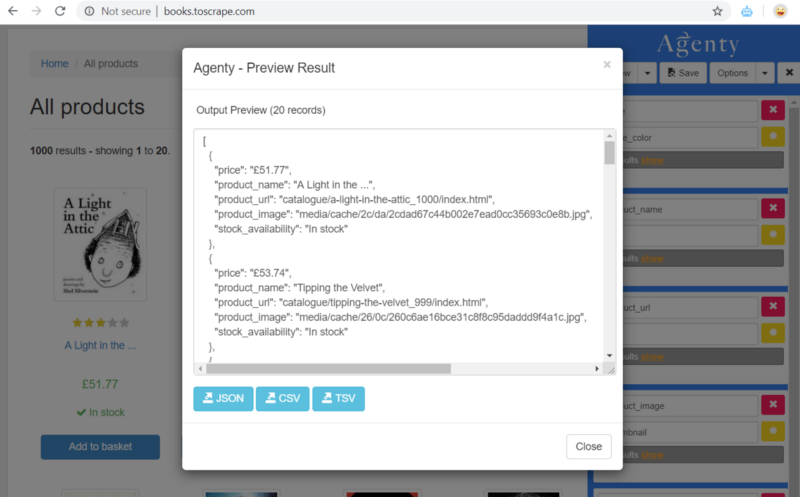
Click on the “Options” button and then “Preview Result” to see the result in JSON format. Or you may also download as delimited file CSV, TSV or JSON to use in your data science project.
Save agent, Pagination, Schedule and the API
Click on the “Save” button and give it a name to save your agent in Agenty cloud to use other advanced web scraping feature like pagination, scheduling, password-protected site crawling and more…

Or get agent result via API :
curl -X GET -H "Content-type: application/json" 'https://api.agenty.com/v2/results/{AGENT_ID}/?apikey={API_KEY}&offset=0&limit=1000'
Wrap up
We have seen how to setup a simple web scraper and get it working quickly, but not all websites are simple. So it’s important to learn how to find CSS selectors manually and the analysis of website structure prior to create your web scraping agent will make it lot easier to scrape even complex websites and use to feed your data science projects.