There are multiple extract options available in Agenty to extract data from websites and one of them is RegEx. While it’s recommended to use CSS selectors when possible, we can’t deny the fact that sometimes Regular Expression(RegEx) is required to extract some content which is not part of HTML but needs to be parsed to get an agent result.
For example, some JavaScript variable values are inside a script tag. In this example, I’ll show you how to extract HTML table fields using Regular Expressions to learn how the RegEx option can be used to extract anything you want from the page content.
Note : Agenty chrome extension can’t be used to set up RegEx match fields, so we need to create a dummy agent or use one from samples agent and then edit that agent in agent editor to add RegEx match fields.
Let’s see how we can parsing HTML using Regular Expressions. In this example, I am going to use this example page : https://cdn.agenty.com/examples/example-1.html
Step 1 : Create a new web scraping agent using chrome extension or use an example agent from samples. Step 2 : Edit the agent in agent editor and go to the Collection > Fields section. Step 3 : Go to the example page (or the page you want to extract) and open the HTML source code in a editor or using “View source” option in browser
HTML Source :
<!DOCTYPE html>
<html>
<head>
<style>
table, th, td {
border: 1px solid black;
border-collapse: collapse;
}
th, td {
padding: 15px;
}
</style>
</head>
<body>
<h1>HTML Table</h1>
<table style="width:60%">
<tbody>
<tr>
<td>Jill</td>
<td>Smith</td>
<td>50</td>
</tr>
<tr>
<td>Eve</td>
<td>Jackson</td>
<td>94</td>
</tr>
<tr>
<td>John</td>
<td>Doe</td>
<td>80</td>
</tr>
<tr>
<td>Altay</td>
<td>Doe</td>
<td>30</td>
</tr>
<tr>
<td>Nick</td>
<td>Smith</td>
<td>34</td>
</tr>
<tr>
<td>Rob</td>
<td>Milbern</td>
<td>45</td>
</tr>
<tr>
<td>Scoot</td>
<td>Sam</td>
<td>65</td>
</tr>
</tbody>
</table>
</body>
</html>
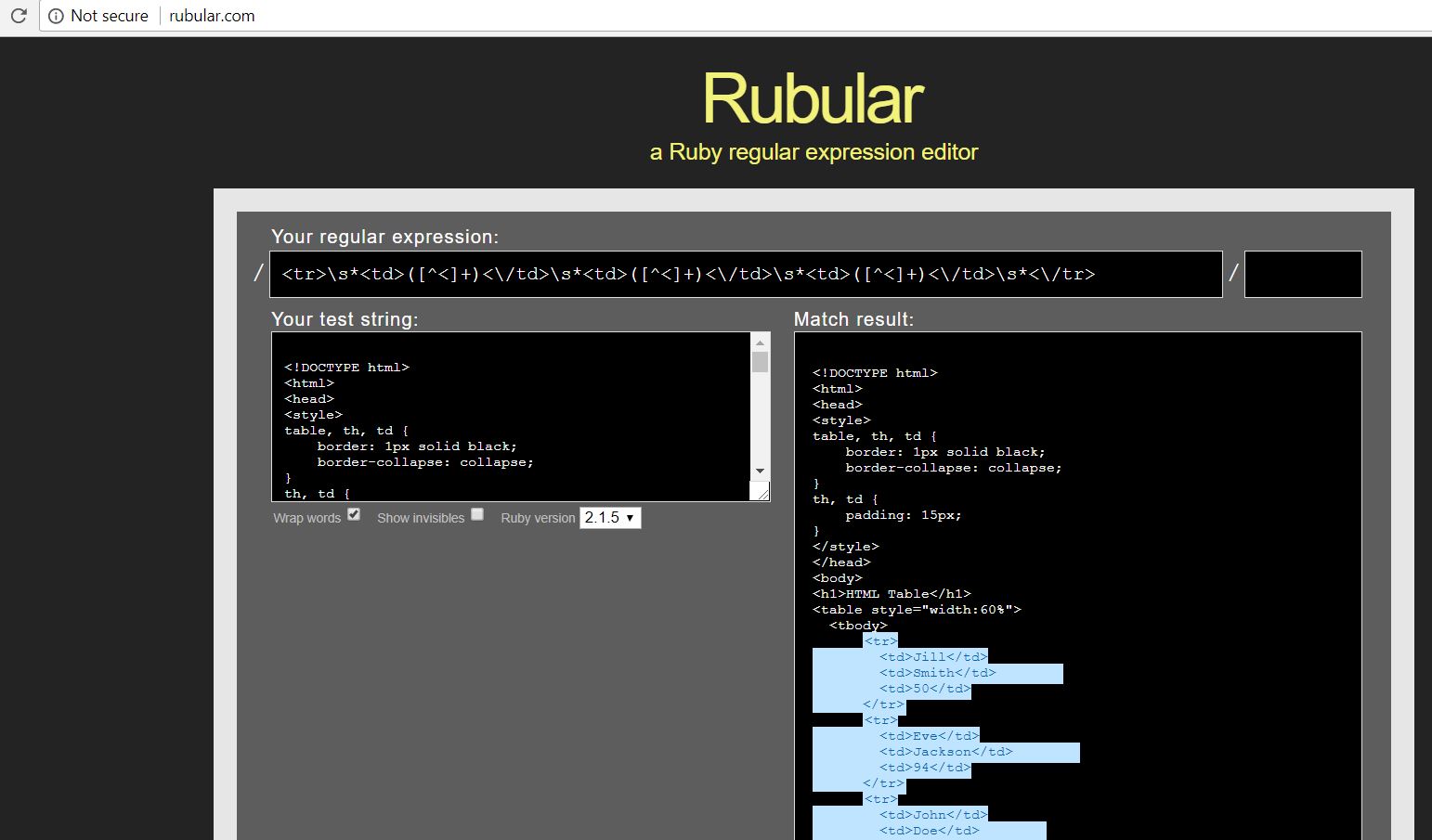
Step 4 : Now use any REGEX editor tool to write and test your REGEX pattern. I am using rubular.com in this example and created this permanent link if you want to try it out - http://rubular.com/r/ubMF1glSP4
Step 5 : Once we have created our Regular Expression. Go to the Agenty’ agent editor and edit the field and paste the expression into the “REGEX pattern” box. Because the regex matches I created are for the entire row (in 3 fields), I can use the same REGEX expression on all 3 fields by changing the “Group Index” to 1, 2 and 3 for the respective fields.
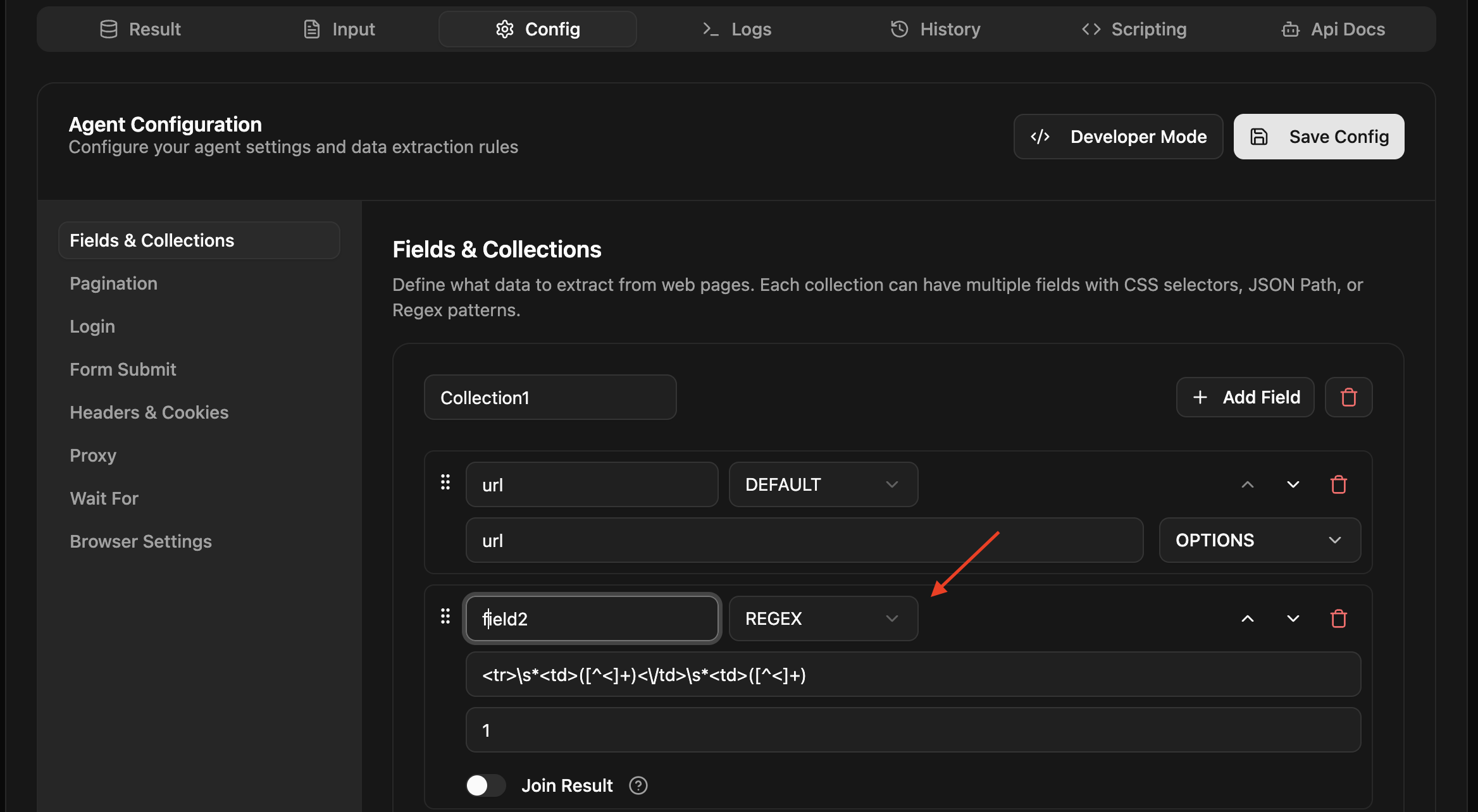
Step 6 : Now, click on the Save button to save the agent configuration and then return back the main agent page.
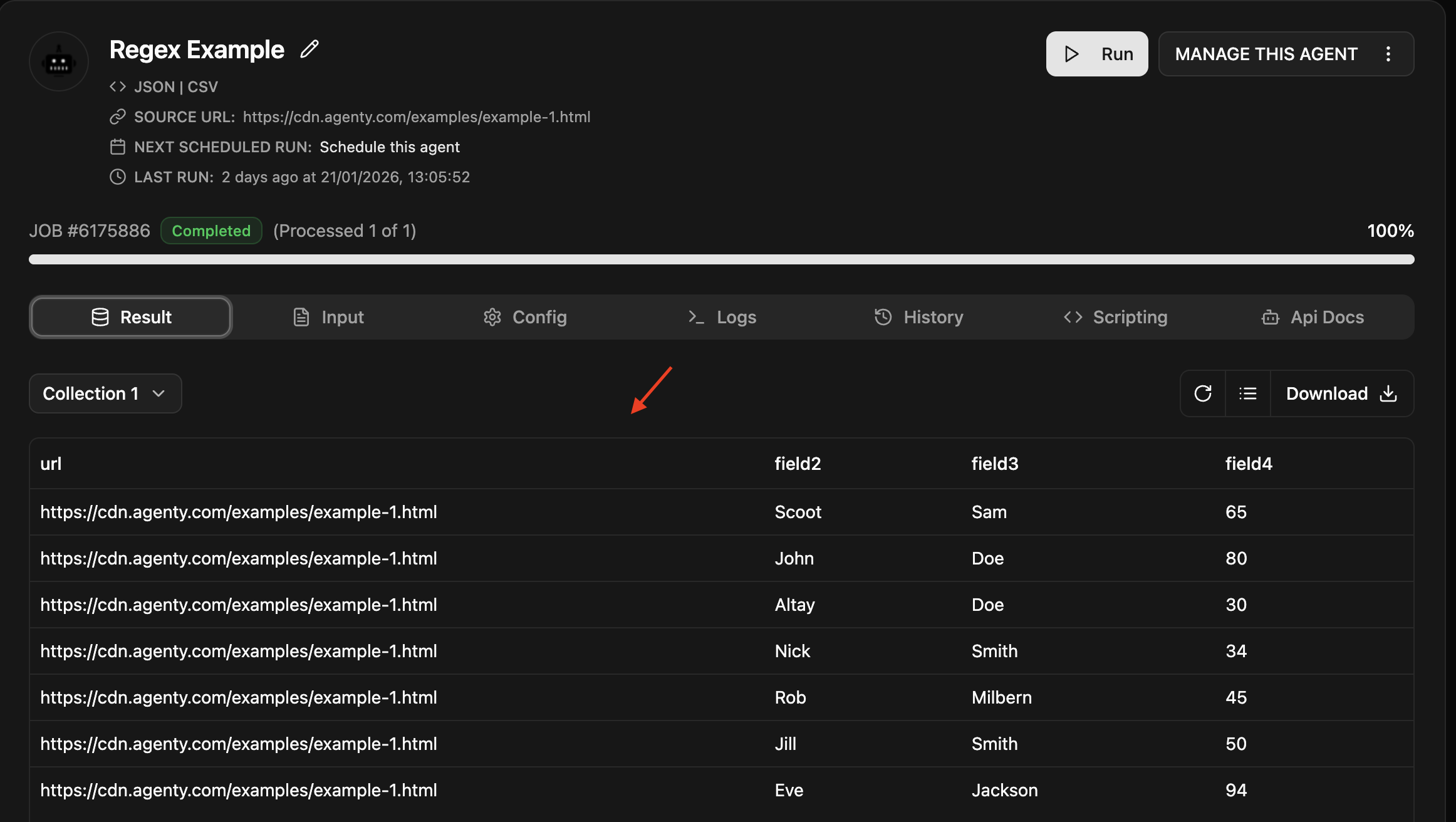
Step 7 : Click on the Run button to start the execution of scraping agent and wait for the job completion. Once the job is completed you can see the extracted result as in screenshot below