How can I perform the hidden data scraping in HTML. The data is there on the HTML head, but those are hidden meta tags with and the value I want to extract can be found on content property.
<meta xmlns:og="http://opengraphprotocol.org/schema/" property="og:upc" content="2633" />
<meta xmlns:og="http://opengraphprotocol.org/schema/" property="product:price:amount" content="419.99" />
<meta xmlns:og="http://opengraphprotocol.org/schema/" property="product:price:currency" content="USD" />
I am able to get the meta tag with ‘meta’ selector but I am not able to scrape the content value within this tag. For example, if I want to get the UPC, I got an empty text in my scraping result.
You can use the Attribute selector to scrape these hidden tags from HTML. You can write your selector manually and then enter the “content” in the attribute name option to scrape efficiently.
To scrape the UPC the selector will be - meta[property=“og:upc”] And then the attribute name will be - content
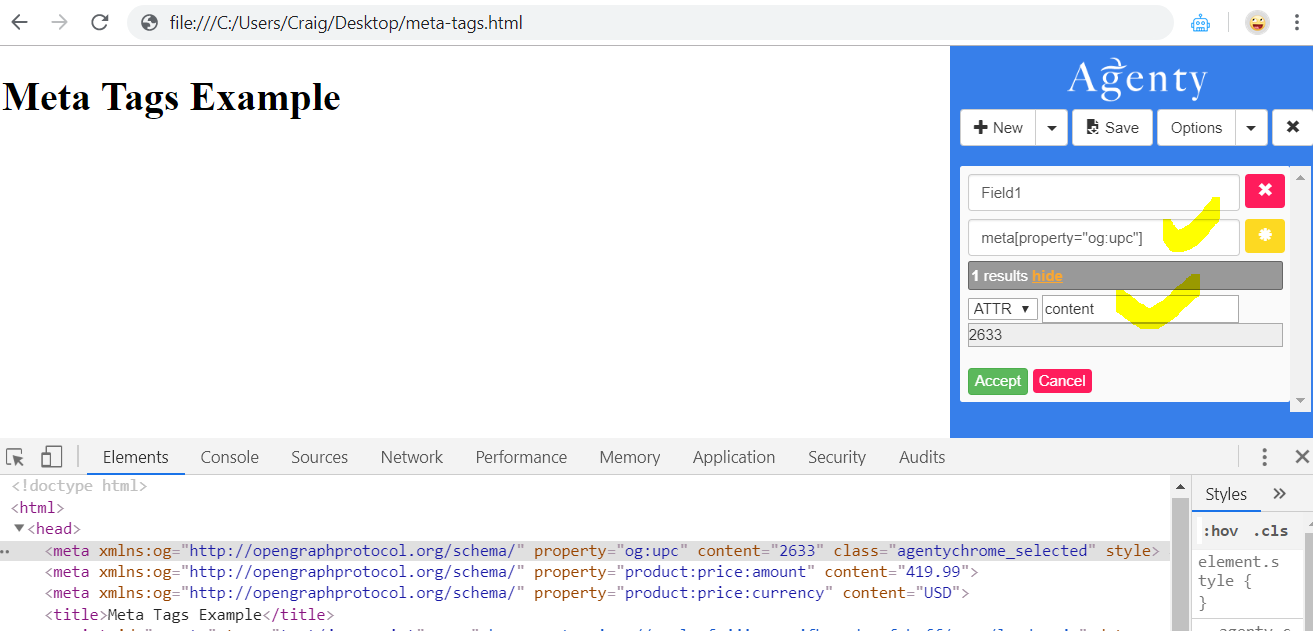
To give you more details, it’s important to use double-quote ("") in the attribute selector when there is a special character in the attribute value you are using in your selector.
For example, if your HTML was like this -
<meta xmlns:og="http://opengraphprotocol.org/schema/" property="upc" content="2633" />
This selector will work to extract this hidden value without double quotes as well -
meta[property=upc]
But if the property value has a special character like “:” as in your case it’s “og:upc”. So, it must be enclosed with quotes to make your selector valid and scrape these hidden elements in meta tags.
<meta xmlns:og="http://opengraphprotocol.org/schema/" property="og:upc" content="2633" />
So, the valid selector is:
meta[property="og:upc"]