In this post, I will show you how to scrape data from unstructured HTML lists, category or search pages to better align the result in the same order as on the source website.
Scraping data from HTML is easy when the webpage is structured as per W3 HTML specification, which is followed by the most of the developers. But, the web is enormous and millions of web developers work everyday to develop websites in hundreds of programming languages.
So, you will see many unstructured HTML websites where some extra efforts are required to parse the data for accurate data scraping.
In this post, I will cover some advance web scraping techniques to show how to use parent, child CSS selectors to be the pro of web scraping.
To better understand with practical example, I have created this test page on github to use in this article.
Just go to this page and try to create a scraping agent with Agenty’s web scraping chrome extension
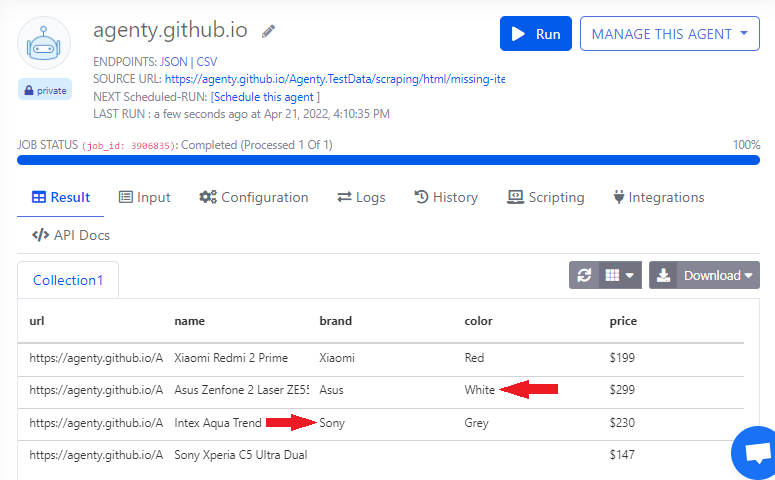
Actual output:
You will see the output is not aligned correctly, a in the source website (refer expected vs actual screenshot) -
Expected output:
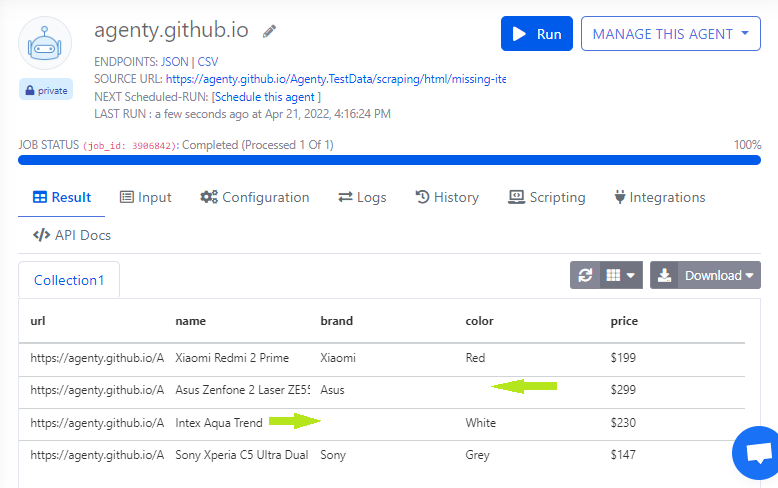
If we check on the test website, there is a list with four items and each item has some attributes.
If you look at the second & third items there is no attribute called Color & Brand respectively, but the scraper moved some cells values from 3rd and 4th item to one up and resulted in order misaligned.
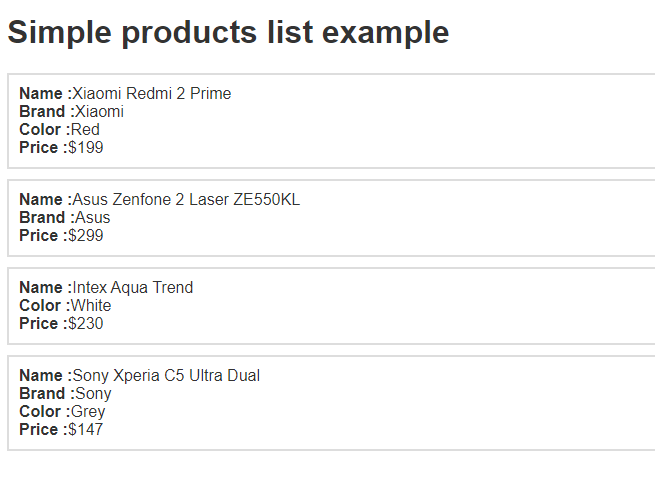
Let’s look at the source code to understand it in a better manner.
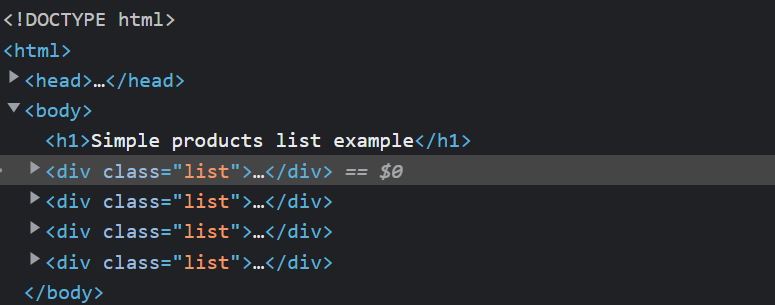
There are four <div> elements associated with the class named list and each div element has another div element inside it where the actual data lies.
As shown in the above pictures, each list has some div elements, but every list does not have the same number of elements. That’s where the problem occurs because the scraping agent uses the querySelectorAll by default, which finds the given selector in the entire page rather than in a particular parent element.
But, there is a solution offered by Agenty to handle complex web scraping - Parent CSS Selector
Parent CSS Selector - What is that? You must be wondering!
A lot of questions come into your mind after reading this word, where can I get it? How would I get to know whether it’s a parent CSS selector or not? And many more…
Wait, I’ll give all the answers to your question which comes to your mind. Firstly Parent CSS Selector is nothing but the outermost element of any inner element. As you can see from the below screenshot.
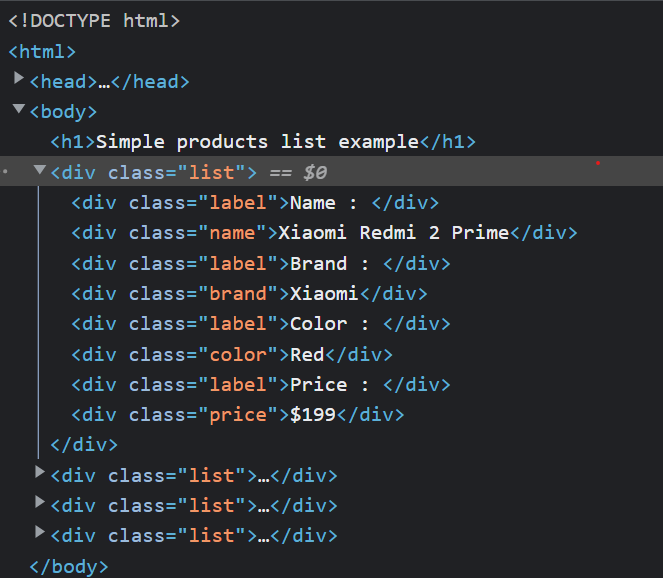
Now, we know the .list is parent for all four products in this page. So using this selector, we can easily solve this problem by specifying the parent CSS selector into the “From” textbox by editing the scraping agent configuration.
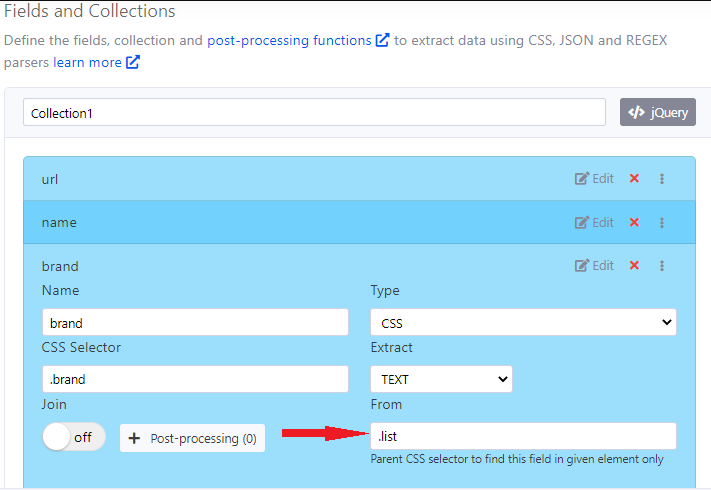
That way, the web scraping software will find the field selector under the given parent element only to apply the querySelectorAll in the selected block and won’t jump on the whole page.
Let’s save and run the web scraping agent again to see the output, it will extract the data correctly as in the expected screenshot.