Fast, scalable and no-code web scraping tool
- 2x better performance in scraping agent with automatic ads and tracker blocking feature
- Puppeteer, Playwright integration with scraping agent to use any external code written in Node.js for cross platform.
- Smart proxies to anonymize each request from thousands of running browsers and never get blocked
- New
/browserAPI for screenshot, pdf, content extraction with simple GET/POST requests in any programming language
New Browser API
New /browser API to capture screenshot, convert website into pdf, content extraction with simple GET/POST requests.
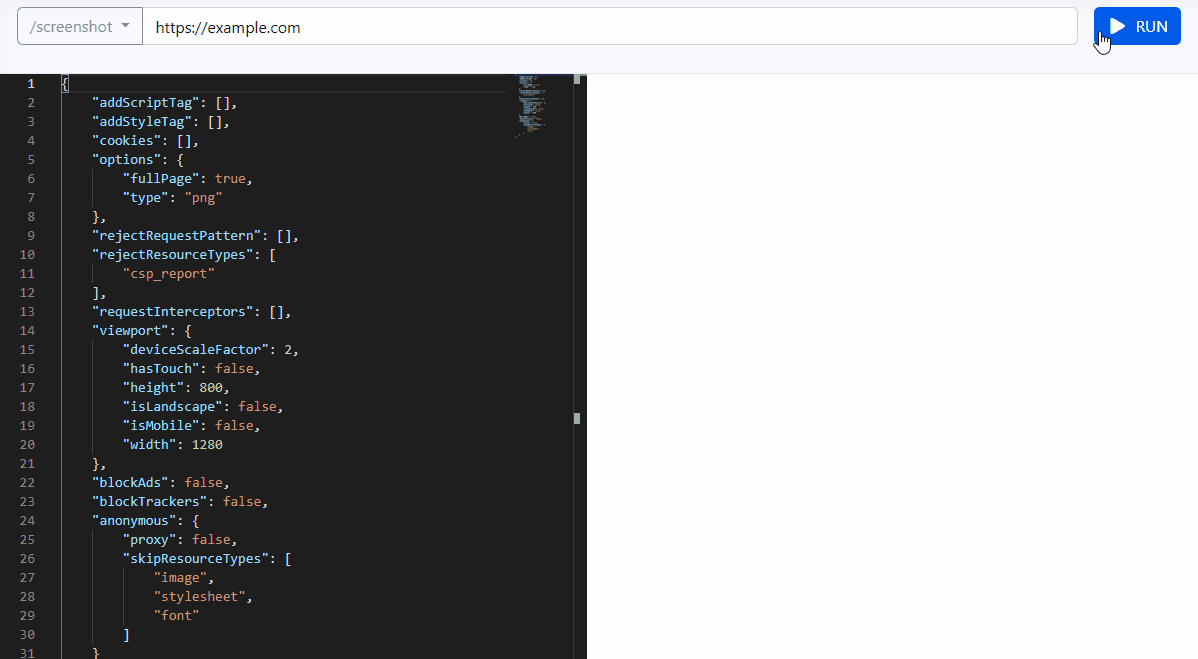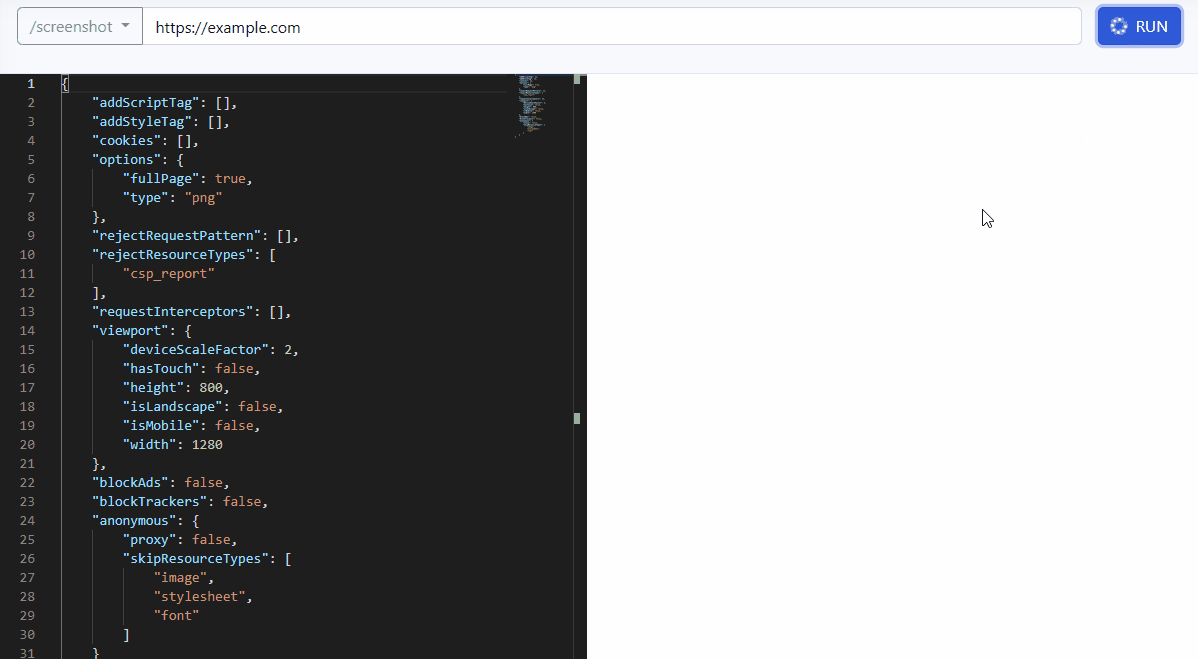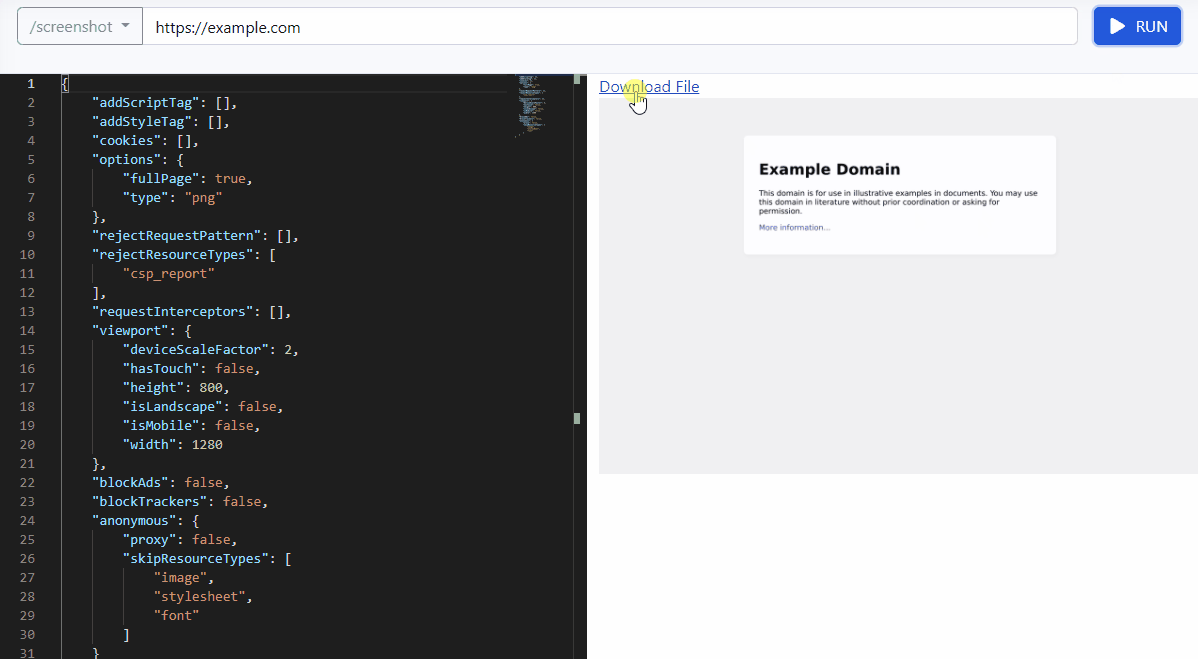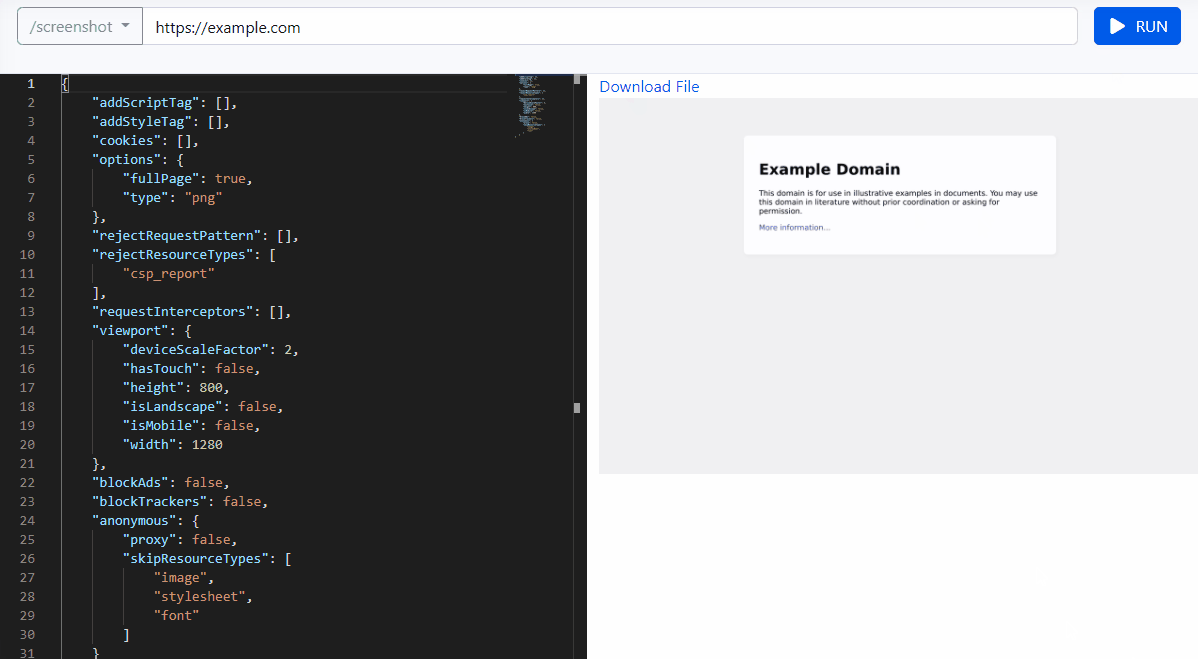
Browser API URL
https://browser.agenty.com
Endpoints -
See the complete documentation here →
Or, Try it here - https://cloud.agenty.com/browser
API Changes
The API routes has been upgraded to v2 from v1 Old URL
https://api.agenty.com/v1
New URL
https://api.agenty.com/v2
There are some other changes in the agent, list level API, please see all the changes in our new API documentation - https://www.agenty.com/docs/api-reference
Scraping agent changes
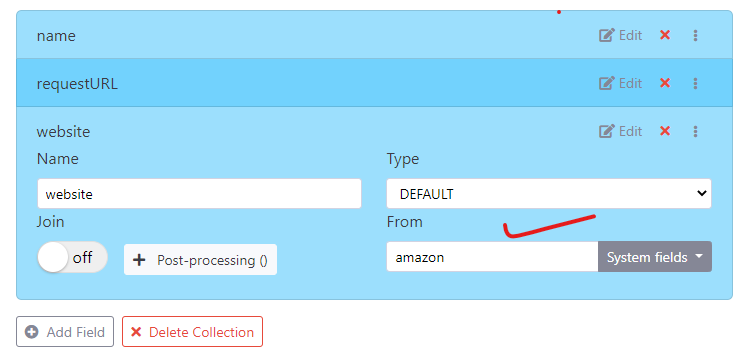
System fields
The default field has a new option called System fields to select system generate fields - For example to capture current page url,statusCode, or the webpage screenshot etc.
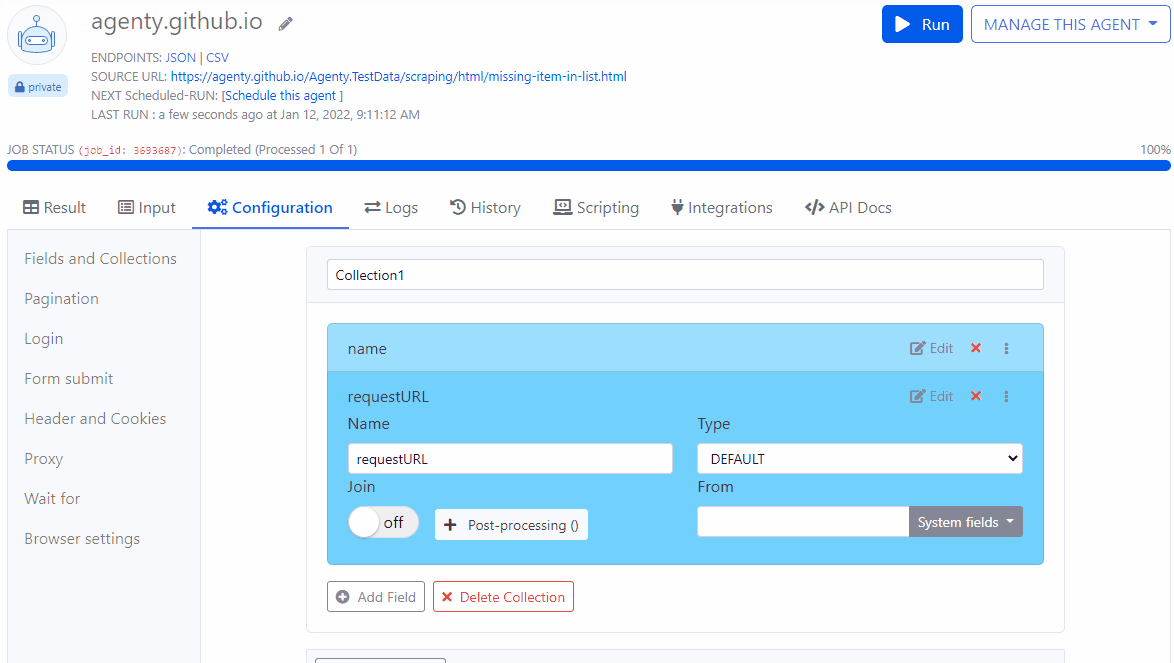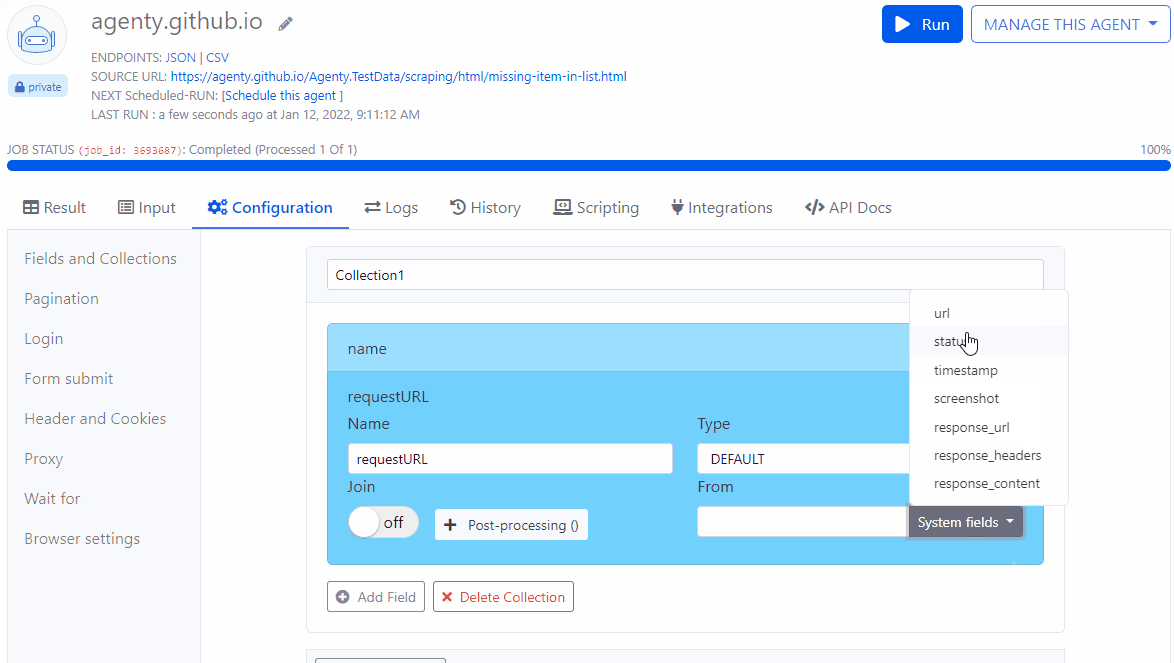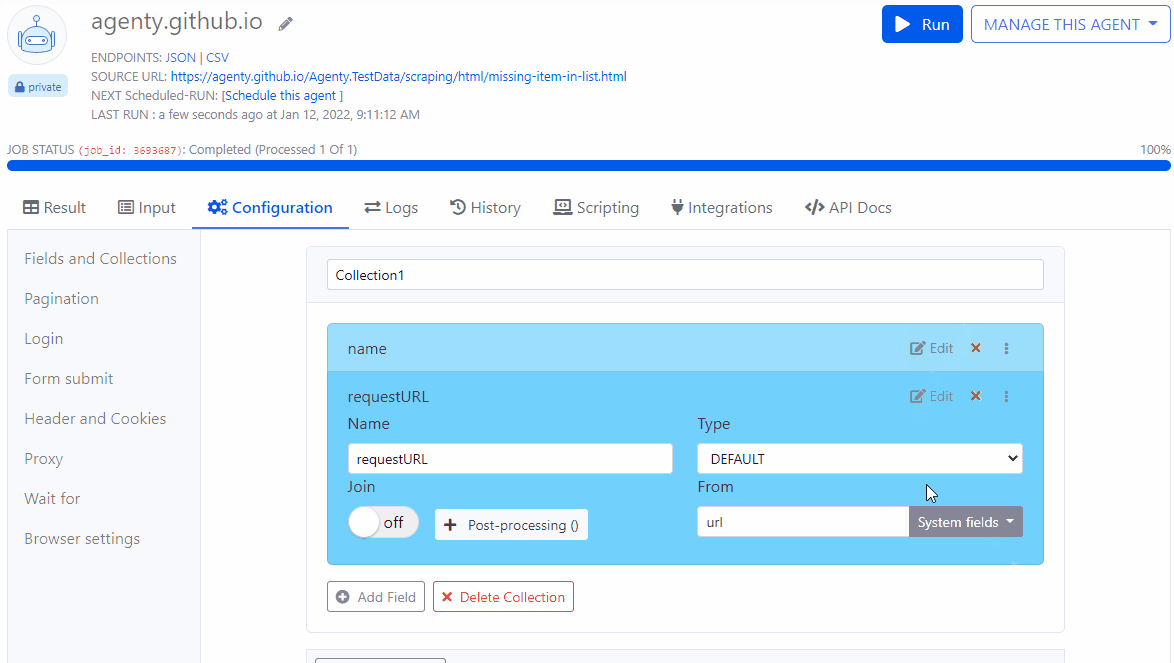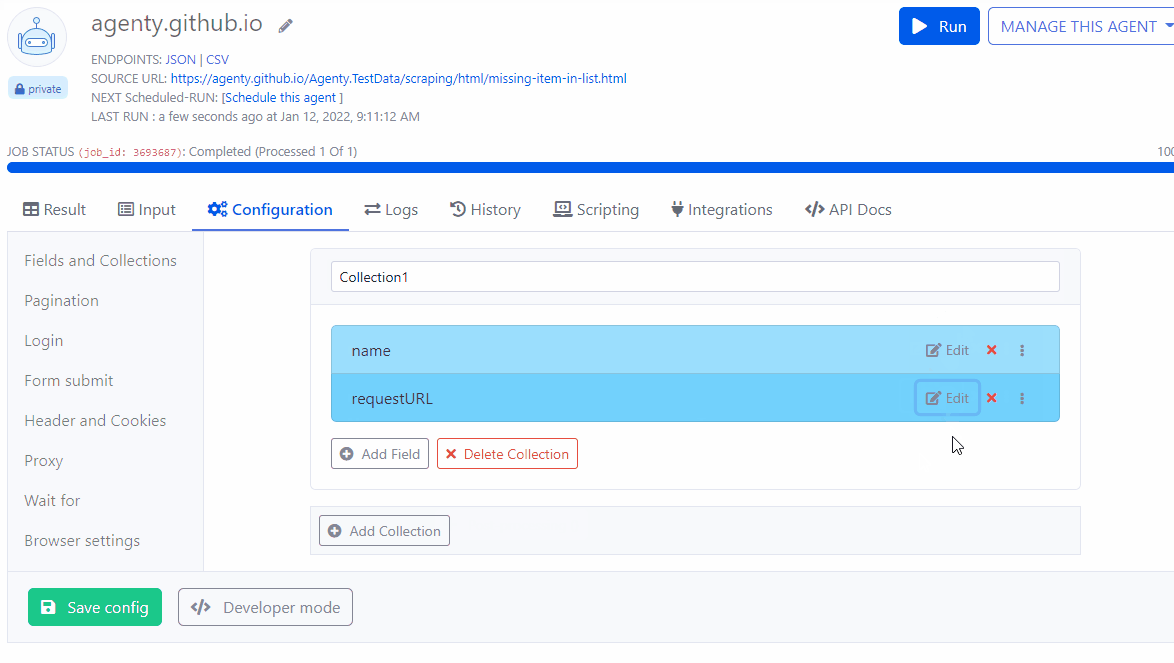
You can also use the default filed to set your static values, for example if I want to add default field with static value as “amazon”
I can just do that with default fields -
JSON Paths
The JSON Path engine has been upgraded to support all latest JSON queries. For example recursive descent and wildcard search is supported now to extract data from JSON APIs.
| JSONPath | Description |
|---|---|
| . or [] | Child operator |
| … | Recursive descent. JSONPath borrows this syntax from ECMAScript 4x. |
| * | Wildcard. All objects/elements regardless of their names. |
See complete documentation here
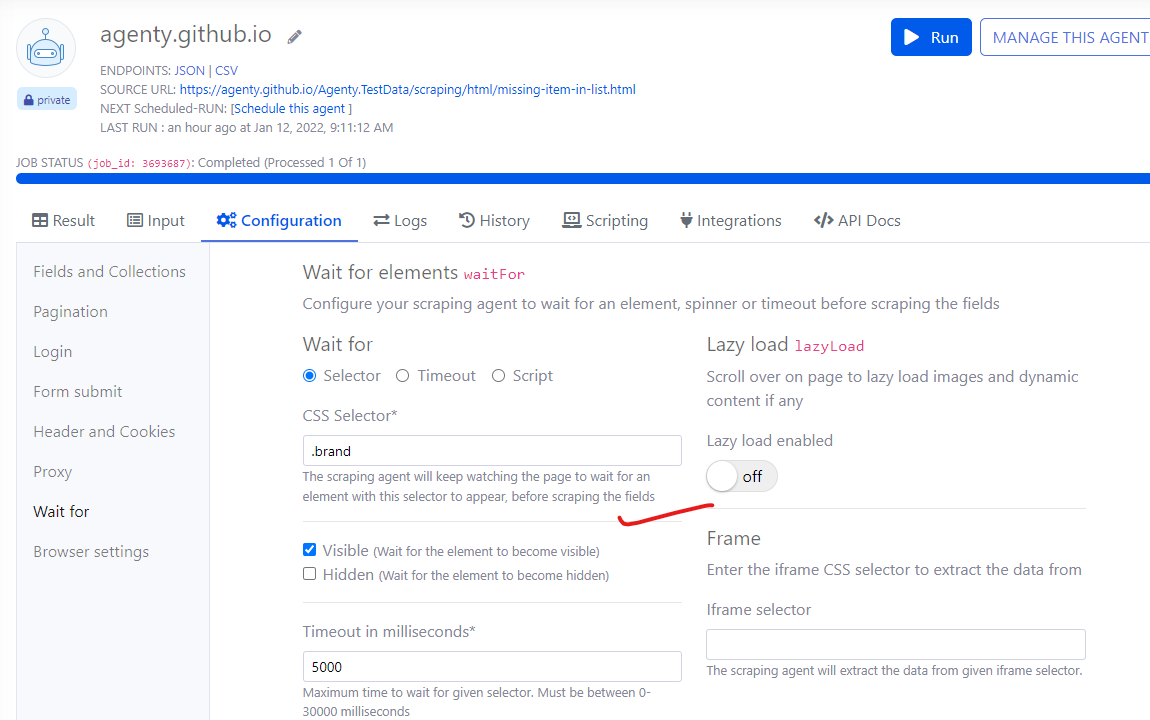
Wait for
We have introduced some new options on wait for element settings under scraping agent.
These options will allow you to better configure your agent to wait for element visible, hidden or fixed timeout to handle dynamic website scraping where actual content is rendered after a few seconds with JavaScript and other client side frameworks.
- Visible - Agenty will wait for the element to be visible, for example you can use this to wait for your products to be properly loaded from all network requests before starting the scraping .
-
Hidden - Agenty will wait for the element to be hidden, for example you can use this wait for
spinnerorloaderelements to be hidden before scraping the data.
Pagination improvement
We have added a new smart change detection algorithm in scraping agent to scrape new items only while paginating through infinite scroll to avoid duplicates and exit the pagination loop if data starts repeating.
New container option in infinite scroll pagination to specify the particular section/div to scroll instead the full page.
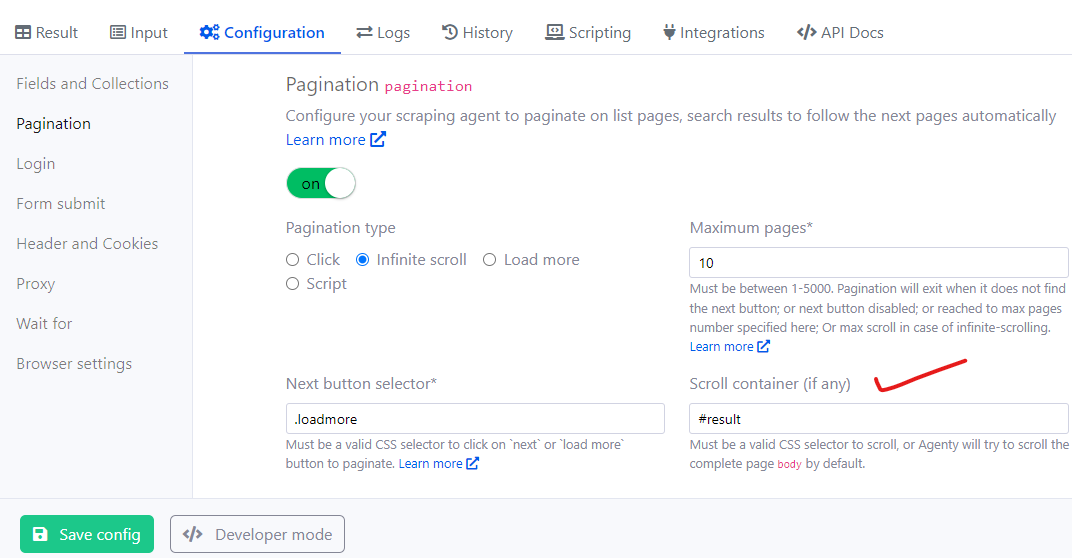
When no container is specified, Agenty will scroll the full page to try loading more items when available.
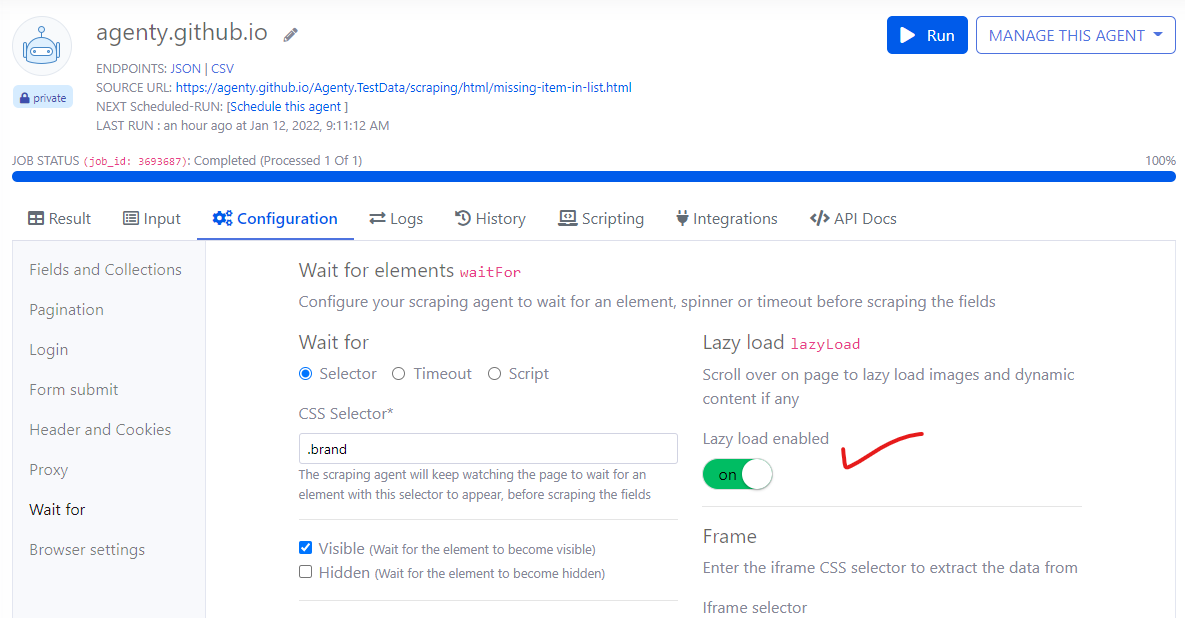
Lazy load
The new lazy load feature has been added in scraping agent to scroll over the page after load to lazy load images, videos, news etc.
If you are using Agenty for capturing screenshots, scraping below the fold content from dynamic websites - Enable this lazy load option to scroll over the page automatically.
Iframe scraping
Now you can specify the iframe selector to extract data from iframe,
By default, Agenty will scrape the data from mainFrame when no selector is specified.
Timeout
The timeout option is now in milliseconds, we’ve updated all existing agents to use the new timeout settings and chrome extension has been configured to create a new agent with milliseconds timeout format.
Scripts
The scripts feature has been completely replaced with a new JavaScript engine to better integrate with our Browser API and improve testability.
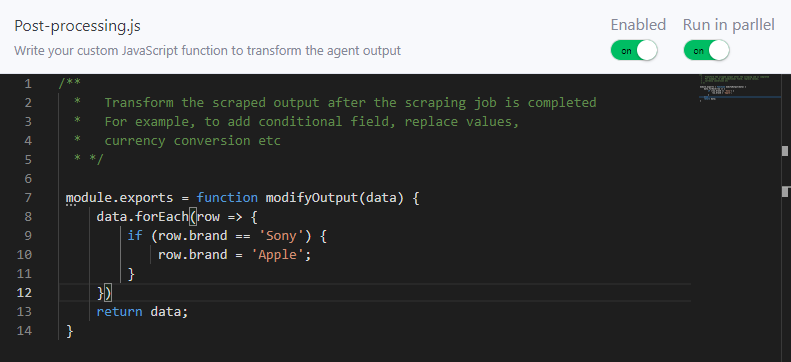
You can use the Post-processing.js to write a custom function to modify the agent result. Now, you can also specify to run your post-processing script in parallel while the agent is running…
Here is the quick example to show if/else use case.
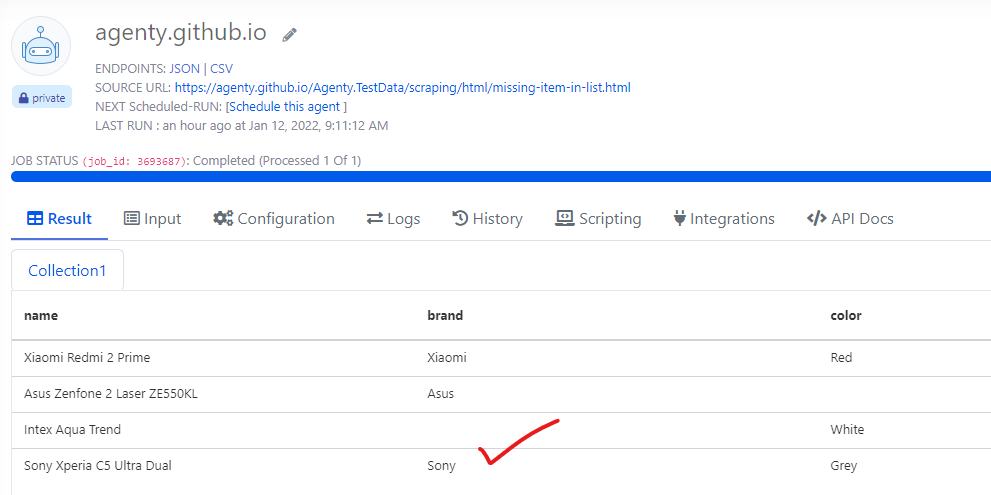
Default scraping result
This is my default web scraping agent result from this sandbox page - https://agenty.github.io/Agenty.TestData/scraping/html/missing-item-in-list.html
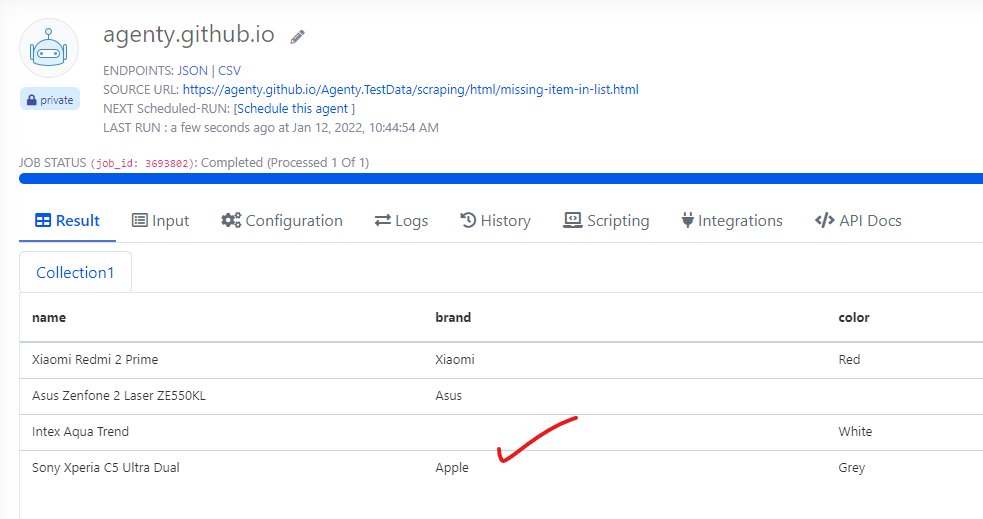
Now, let’s say I want to change the brand name to Apple where it’s Sony on the web page, or maybe more complex logic to set some value in empty cells where the brand name is not specified.
Script
Here, I’ve written a custom function to set the brand name to Apple from Sony.
module.exports = function modifyOutput(data) {
data.forEach(row => {
if (row.brand == 'Sony') {
row.brand = 'Apple';
}
})
return data;
}
After script result
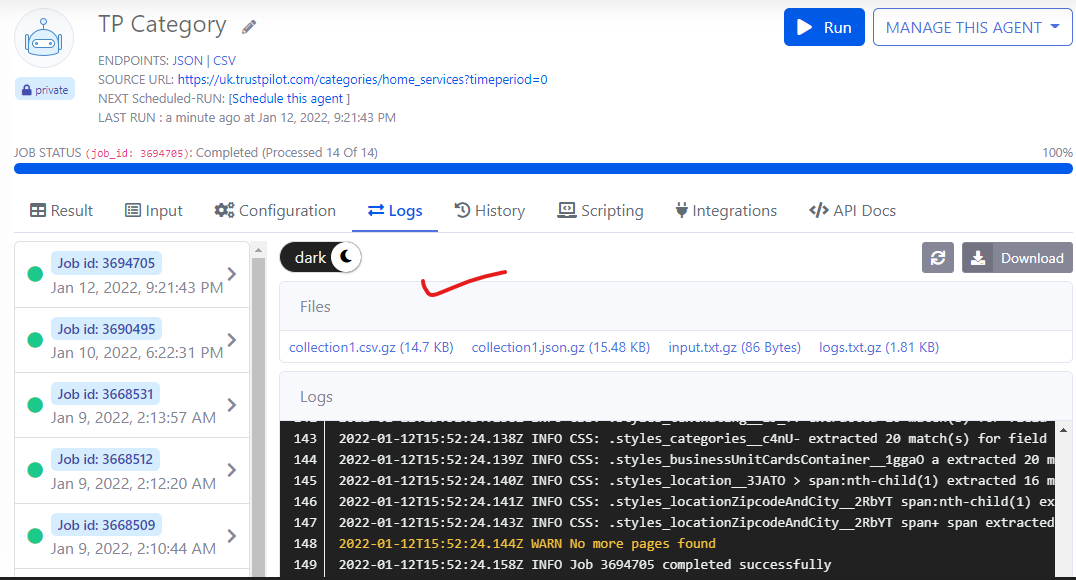
Logs and files
The logging feature has been improved to show logs in plain text mode with color coding to display warnings and errors in orange and red colors.
Additionally, we’ve added the new Files section above the logs to show the list of downloadable files created by the Agenty while executing the job.
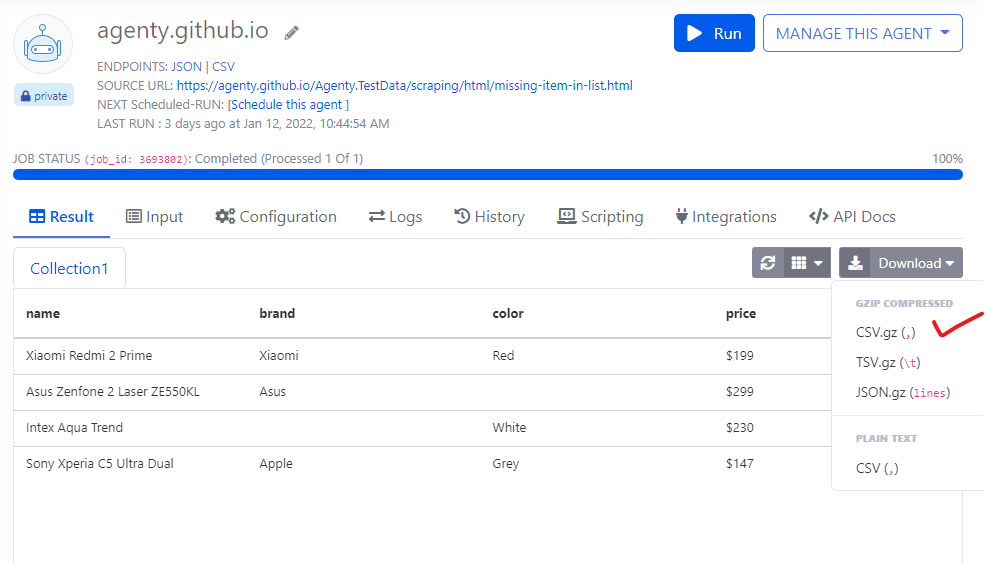
Gzip compressed download
The result download feature performance has been improved by enabling the Gzip compression to download the compressed job result.
You may still download your agent’s result in plain text CSV format, by clicking on the CSV download button under Download drop-down.
Post processing functions
Some of the least-used post-processing functions have been removed to keep the list short and more focused on quick data transform without writing custom JavaScript functions for simple replace, append values etc.
Relative to absolute links
The scraping agent has been improved to extract absolute links by default, so no need to use the Insert function anymore to convert relative URL into absolute links as we were doing on Agenty v1.
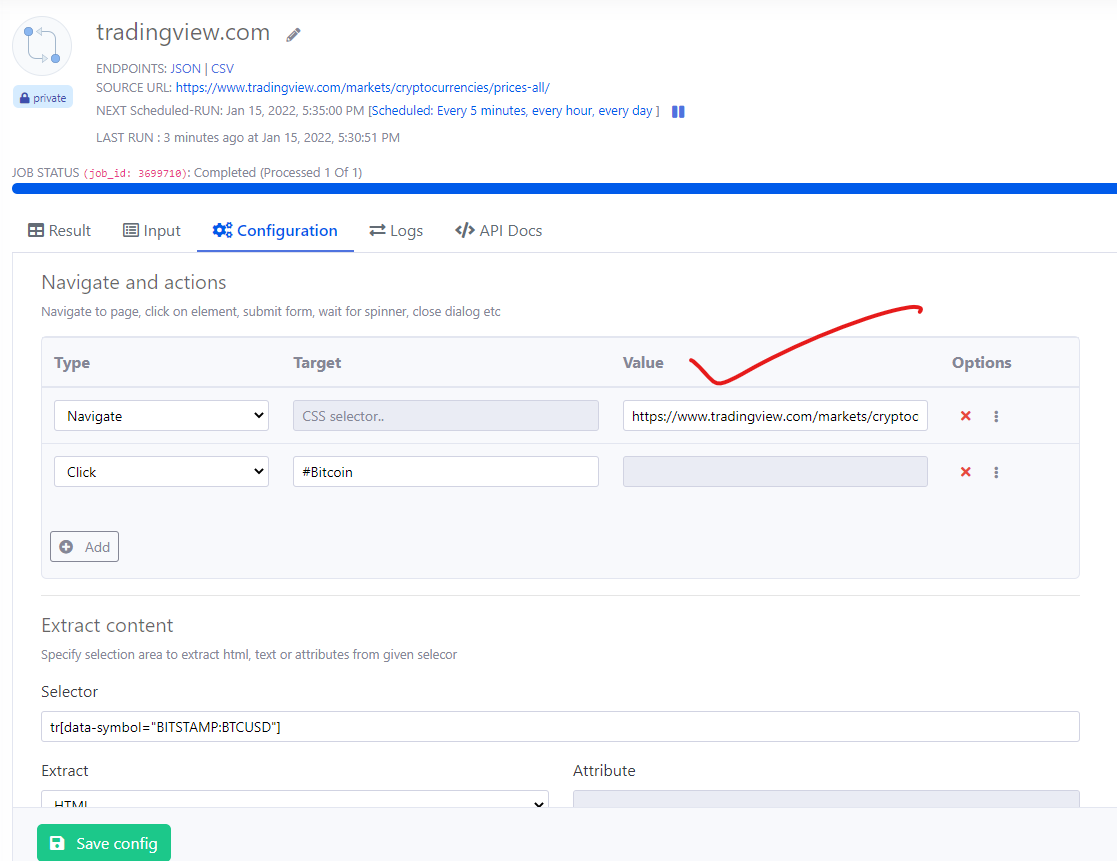
Change detection improvement
The change detection agent has been upgraded with new form submit feature to add custom actions like clicking on a button, scrolling down, login to website before selecting an element for change detection.
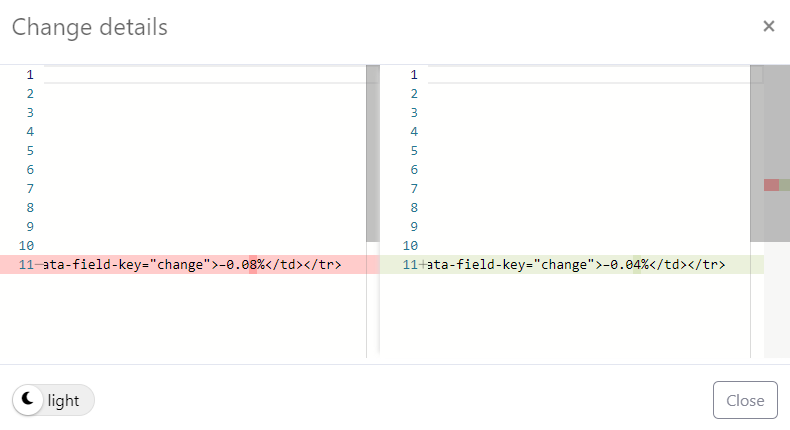
Additionally, the comparison view has also been improved with GitHub style HTML comparison to find differences line by line
The change detection software now supports batch URL monitoring as well to monitor bulk URLs in the single agent with a common selector/element to watch and get an alert for changes.
Native integrations
Now, we have native apps for Shopify, Dropbox and Google to connect an authorized Agenty with your account for ETL process to automatic extract, transform and load the data on your integrated location.
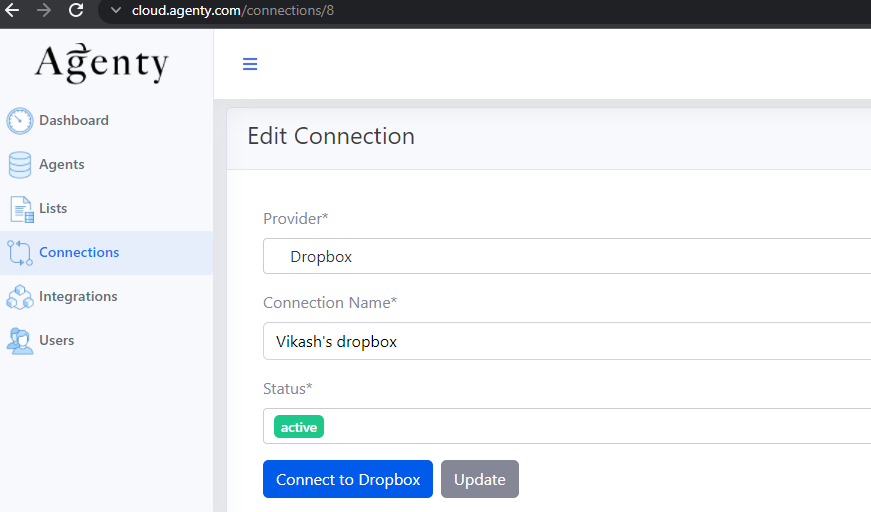
So, if you were using the integration on older version Agenty. Make sure to re-connect it using the new Connection feature and then select that connection on your integration attached with the agent.
Chrome extension - v2.9.3
The chrome extension has been upgraded to version 2.9.3 with many improvements
- URL field is added by default on new agents
- Fixed a bug causing Preview/Export CSV broken for 1000+ rows
- Improved CSS selector finder
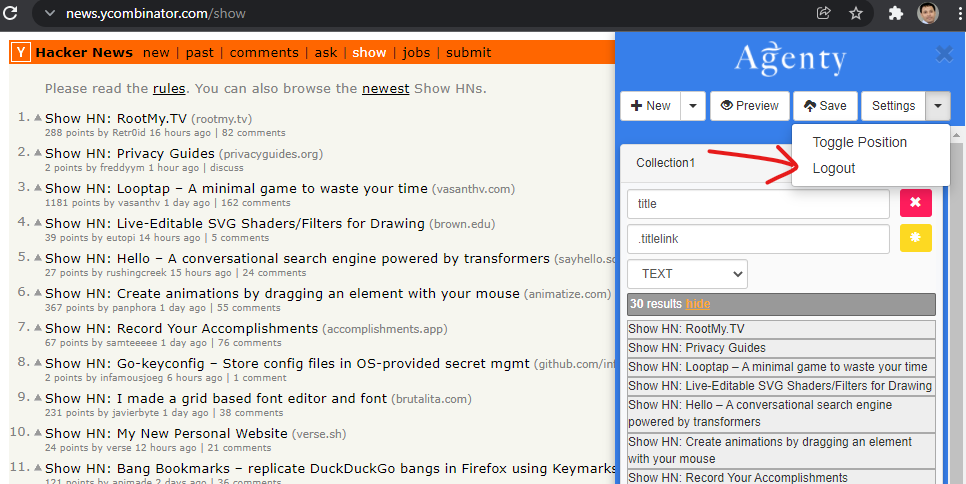
Note: If you get an error saying “Unauthorized request”, please logout and login again. We are working on a fix to increase the session timeout for Chrome extension for longer duration.
If you have any feedback or suggestion, open an issue on our public roadmap on GitHub or contact support.