Convert any website into API using our Puppeteer and Playwright Restful service for automated web scraping allow you to write custom function in Node.js and execute that by sending a POST request handled by hundreds of headless browsers running on Agenty’s cloud machines.
Try your Puppeteer or Playwright code here - https://cloud.agenty.com/browser
The /function API support HTTP POST method to execute your puppeteer code and return the result. You can use the request object to pass the dynamic variables like url
Schema
See complete schema here on github
{
"code" : "Your code here"
"request" : {
// The request object will be passed to your function
// Add url, selector etc to use in your code
}
}
Here are 2 puppeteer examples with code and API usage
Example 1
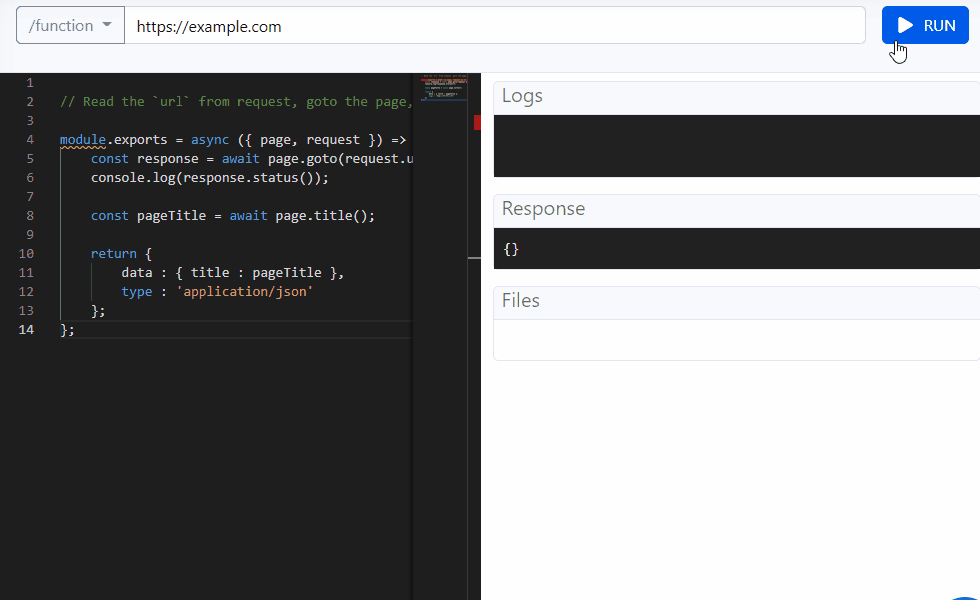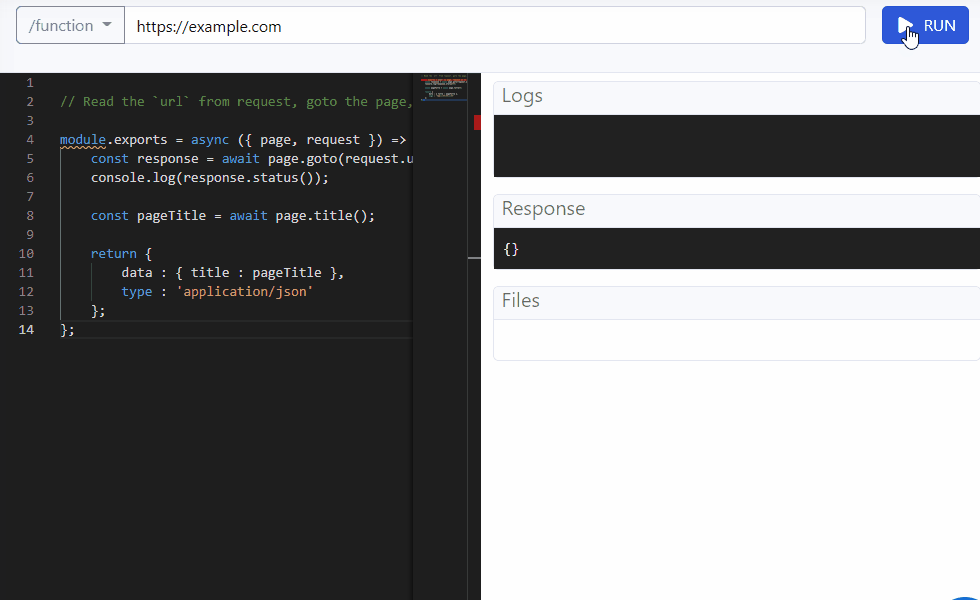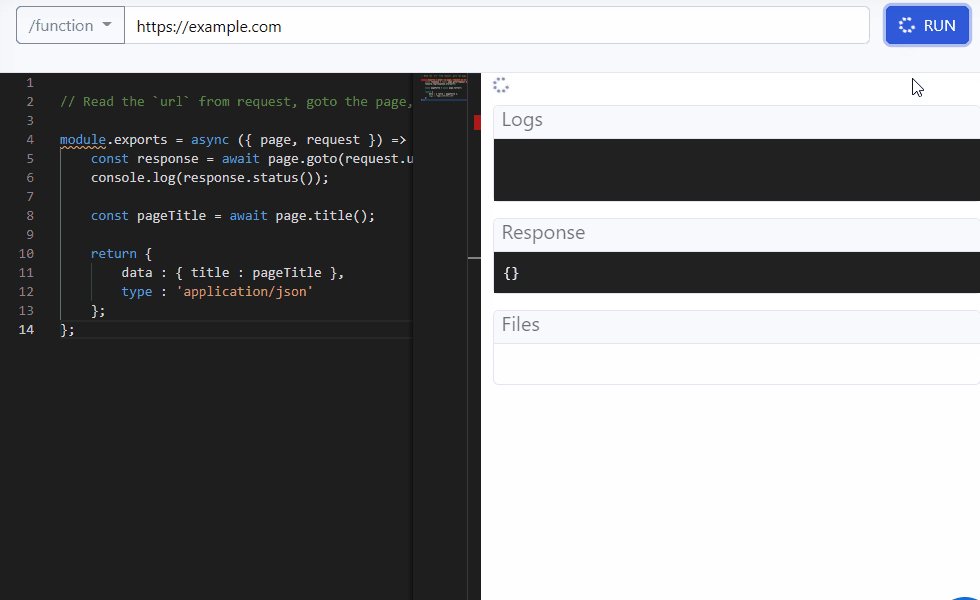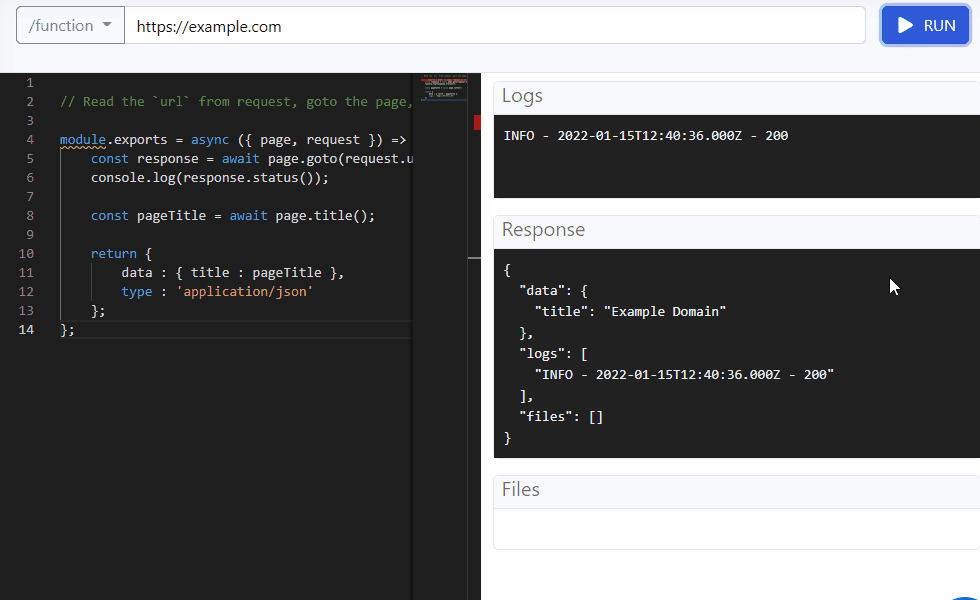
Read the url from request, goto the page, print status on console, extract title and return the results
Code
// Read the `url` from request, goto the page, extract title and return the results
module.exports = async ({ page, request }) => {
const response = await page.goto(request.url);
console.log(response.status());
const pageTitle = await page.title();
return {
data : { title : pageTitle },
type : 'application/json'
};
};
API
const fetch = require('node-fetch');
const body = {
"code": "\n// Read the `url` from request, goto the page, extract title and return the results\n\nmodule.exports = async ({ page, request }) => {\n const response = await page.goto(request.url); \n \n console.log(response.status());\n \n const result = {\n url : response.url(),\n status : response.status(),\n title : await page.title(),\n };\n \n return {\n data : result,\n type : 'application/json'\n }; \n};",
"request": {
"url": "http://books.toscrape.com/"
}
};
fetch('https://browser.agenty.com/api/function?apiKey={{API_KEY}}', {
method: 'post',
body: JSON.stringify(body),
headers: { 'Content-Type': 'application/json' },
})
.then(res => res.json())
.then(json => console.log(json));
Response
{
"data": {
"title": "All products | Books to Scrape - Sandbox"
},
"logs": [
"INFO - 200"
],
"files": []
}
Example 2
Read the url from request, goto the page, print status on console, extract 5 products fields, capture screenshot and return the results
Code
// Read the `url` from request, goto the page, extract products
// capture screenshot and return the results
module.exports = async ({ page, request }) => {
const response = await page.goto(request.url);
console.log(response.status());
const result = await page.evaluate(() => {
const data = [];
var products = document.querySelectorAll('.product_pod');
for (var product of products) {
data.push({
product_name: product.querySelector('h3').textContent,
product_price: product.querySelector('.price_color').textContent,
product_availability: product.querySelector('.availability').textContent,
product_image: "http://books.toscrape.com" + product.querySelector('.thumbnail').getAttribute("src"),
product_link: "http://books.toscrape.com" + product.querySelector('h3 > a').getAttribute("href")
});
}
return data;
});
await page.screenshot({ path: 'page1.png', fullPage: true });
return {
data: result,
type: 'application/json'
};
};
API
const fetch = require('node-fetch');
const body = {
"code": "// Read the `url` from request, goto the page, extract products\n// capture screenshot and return the results\n\nmodule.exports = async ({ page, request }) => {\n const response = await page.goto(request.url);\n console.log(response.status());\n const result = await page.evaluate(() => {\n const data = [];\n var products = document.querySelectorAll('.product_pod');\n for (var product of products) {\n data.push({\n product_name: product.querySelector('h3').textContent,\n product_price: product.querySelector('.price_color').textContent,\n product_availability: product.querySelector('.availability').textContent,\n product_image: \"http://books.toscrape.com\" + product.querySelector('.thumbnail').getAttribute(\"src\"),\n product_link: \"http://books.toscrape.com\" + product.querySelector('h3 > a').getAttribute(\"href\")\n });\n }\n return data;\n });\n\n await page.screenshot({ path: 'page1.png', fullPage: true });\n\n return {\n data: result,\n type: 'application/json'\n };\n};",
"request": {
"url": "http://books.toscrape.com/"
}
};
fetch('https://browser.agenty.com/api/function?apiKey={{API_KEY}}', {
method: 'post',
body: JSON.stringify(body),
headers: { 'Content-Type': 'application/json' },
})
.then(res => res.json())
.then(json => console.log(json));
Response
{
"data": [
{
"product_name": "A Light in the ...",
"product_price": "£51.77",
"product_availability": "In stock",
"product_image": "http://books.toscrape.commedia/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg",
"product_link": "http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html"
},
{
"product_name": "Tipping the Velvet",
"product_price": "£53.74",
"product_availability": "In stock",
"product_image": "http://books.toscrape.commedia/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg",
"product_link": "http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html"
},
...
],
"logs": [
"INFO - 200"
],
"files": [
{
"type": "image/png",
"url": "https://s3.amazonaws.com/us-east-1.data.agenty.com/temp/2020/5/3/mvn83f-page1.png"
}
]
}
Proxy
The /function API has the built-in proxy support and you can use the anonymous.proxy property to set if proxy should be used for your request for anonymous website scraping
{
"code" : "Your code here"
"request" : {
// The request object will be passed to your function
// Add url, selector etc to use in your code
},
"anonymous" {
"proxy" : true,
}
}
Packages
Following built-in and NPM packages are whitelisted under /function API to use for your scripting requirement.
- url
- fs (Limited access granted for
readFileSync,writeFileSync,unlinkSync,createWriteStreamonly) for security purpose - node-fetch
- neat-csv
- loadash
To use a package, just define it in your code - for example
const fetch = require('node-fetch');