Sitemap Crawler
Retrieve all links from a website sitemap automatically
Frequently asked questions
What is a Sitemap Crawler Tool?
Our Sitemap Crawler Tool is a web crawler sitemap extractor that reads a website's XML sitemap and retrieve all the links to convert the sitemaps into a spreadsheet format
How does an XML Sitemap Crawler work?
The XML Sitemap Crawler works in two ways:
- Provide a direct sitemap URL: You can enter the exact
sitemap.xmlURL, and the tool will fetch it and extract all links from that file (and any sitemap index it references). - Auto-discover sitemaps (default): With
findSitemaps: trueenabled, the crawler checks the site'srobots.txtfile and common sitemap locations to automatically find and load the sitemap for you.
In both cases, the web crawler parses every sitemap entry and follows sitemap indexes to extract all URLs across the site.
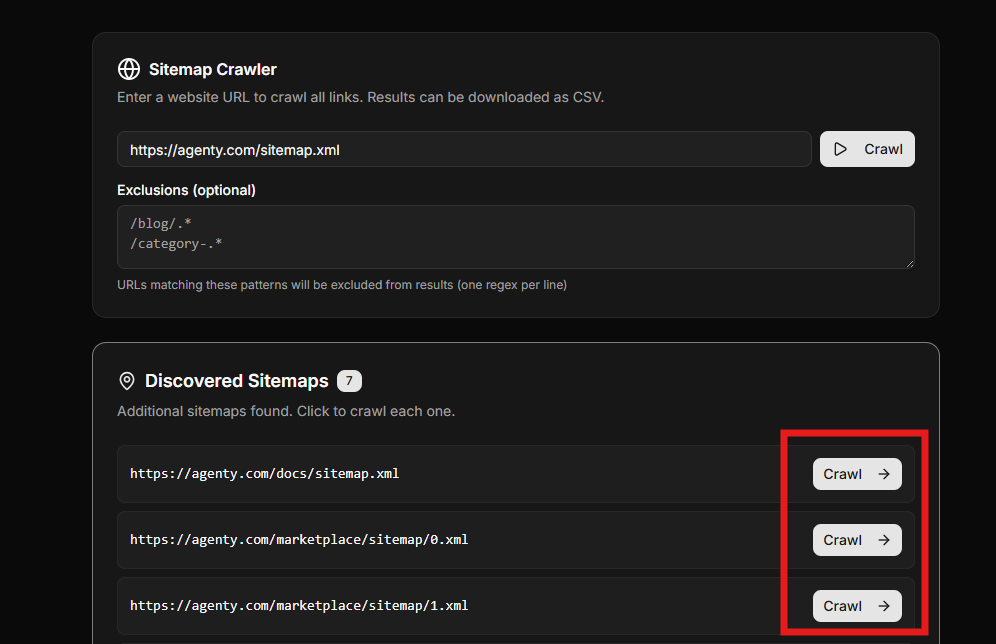
Does the Sitemap Crawler support recursive sitemap crawling?
Yes. When the crawler discovers a sitemap index or additional sitemap files, it automatically lists all available sitemaps found on the site.
You can then choose to crawl those sitemaps recursively. Each selected sitemap is fetched and parsed in turn, allowing the sitemap crawler tool to extract URLs across large and multi-level sitemap structures.
Can this web crawler sitemap tool handle large websites?
Yes. The tool supports sitemap indexes and large XML sitemap files, making it suitable for websites crawling with thousands or even millions of URLs .