How can scrape drop down list and exclude the 1st option from the select to extract values. Because the first label is a general label asking to select one of the option in HTML and when I scrape the items using the .items option selector all the values are coming.
<select name="items">
<option value="0">--Select an item--</option>
<option value="1">Item 1</option>
<option value="2">Item 2</option>
<option value="3">Item 3</option>
</select>
Now, how can I exclude the <option value="0">--Select an item--</option> from my scraping result, instead deleting it manually later on from the CSV file. Let’s see…
You may use the :not selector to ignore the 1st option from the dropdown. All you need to do is use the :not selector with the :first-child combination like this - option:not(:first-child)
So your final selector to scrape the drop-down items excluding the 1st option will be : select[name=“items”] option:not(:first-child)

I created a Github example page for your testing, and then tested with a scraping agent - it works fine 
https://agenty.github.io/Agenty.TestData/forum/forum-30.html
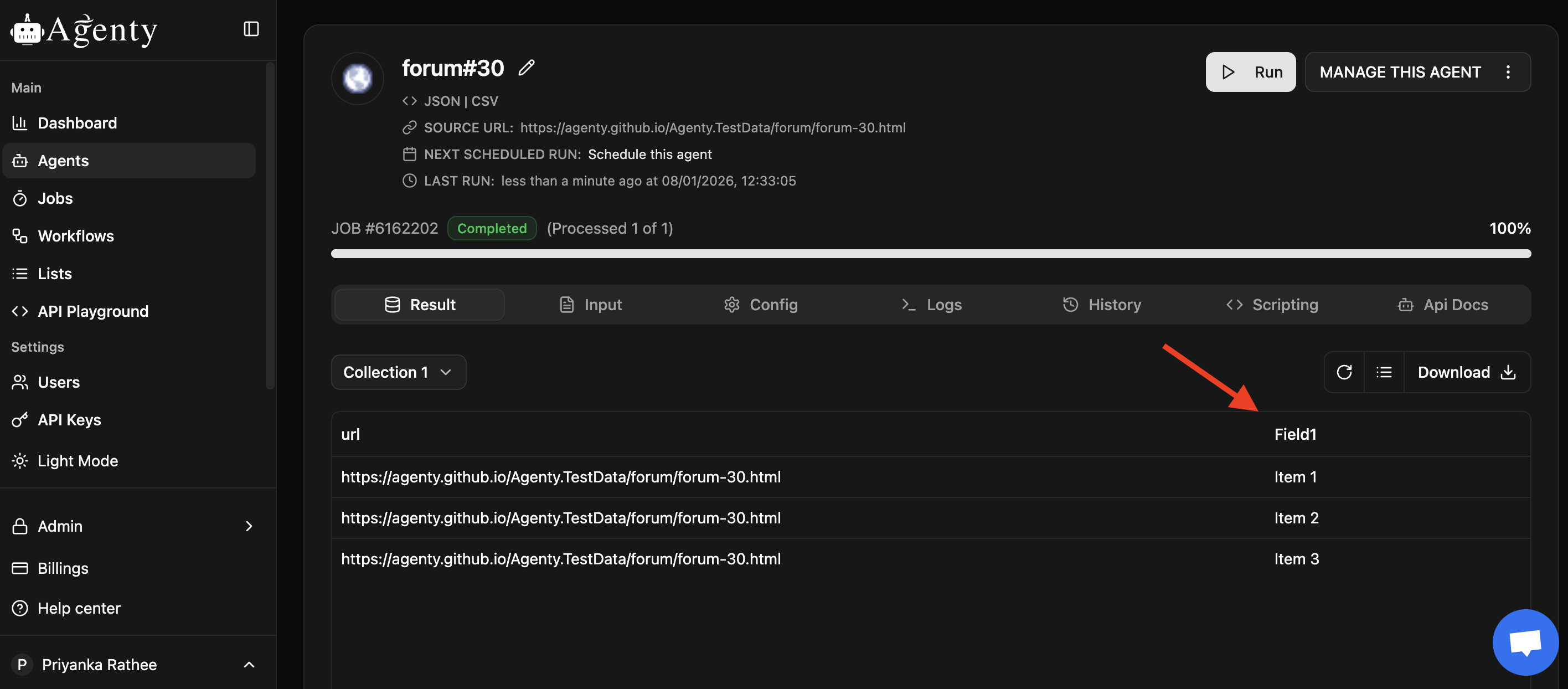
Here are docs on mozilla to learn more : https://developer.mozilla.org/en-US/docs/Web/CSS/:not https://developer.mozilla.org/en-US/docs/Web/CSS/:first-child